作者:解学武
矩阵加法(基于十字链表)及C语言代码实现


矩阵之间能够进行加法运算的前提条件是:各矩阵的行数和列数必须相等。
在行数和列数都相等的情况下,矩阵相加的结果就是矩阵中对应位置的值相加所组成的矩阵,例如:
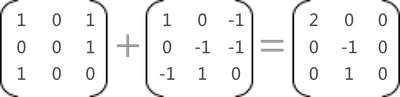
采用链式存储结构存储稀疏矩阵三元组的方法,称为“十字链表法”。

用结构体自定义表示为:
所以,采用结构体自定义十字链表的结构,为:
对应行链表的位置确定之后,判断数据元素 A 在对应列的位置:
实现代码:
设指针 pa 和 pb 分别表示矩阵 A 和矩阵 B 中同一行中的结点( pb 和 pa 都是从两矩阵的第一行的第一个非0元素开始遍历),针对上面的三种情况,细分为 4 种处理过程(第一种情况下有两种不同情况):
实现代码:
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
在行数和列数都相等的情况下,矩阵相加的结果就是矩阵中对应位置的值相加所组成的矩阵,例如:
图1 矩阵相加
十字链表法
之前所介绍的都是采用顺序存储结构存储三元组,在类似于矩阵的加法运算中,矩阵中的数据元素变化较大(这里的变化主要为:非0元素变为0,0变为非0元素),就需要考虑采用另一种结构——链式存储结构来存储三元组。采用链式存储结构存储稀疏矩阵三元组的方法,称为“十字链表法”。
十字链表法表示矩阵
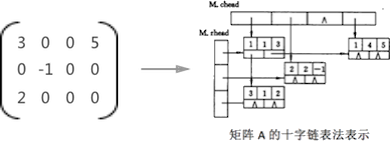
例如,用十字链表法表示矩阵 A ,为:
图2 矩阵用十字链表法表示
由此可见,采用十字链表表示矩阵时,矩阵的每一行和每一个列都可以看作是一个单独的链表,而之所以能够表示矩阵,是因为行链表和列链表都分别存储在各自的数组中
图 2 中:存储行链表的数组称为 rhead 数组;存储列链表的数组称为 chead 数组。
十字链表中的结点
从图2中的十字链表表示矩阵的例子可以看到,十字链表中的结点由 5 部分组成:
图3 十字链表中的结点
指针域A存储的是矩阵中结点所在列的下一个结点的地址(称为 “down域”);
指针域B存储的是矩阵中该结点所在行的下一个结点的地址(称为 “right域”);
指针域B存储的是矩阵中该结点所在行的下一个结点的地址(称为 “right域”);
用结构体自定义表示为:
typedef struct OLNode
{
int i,j,e; //矩阵三元组 i 代表行 j 代表列 e 代表当前位置的数据
struct OLNode *right,*down; //指针域 右指针 下指针
}OLNode,*OLink;
十字链表的结构
使用十字链表表示一个完整的矩阵,在了解矩阵中各结点的结构外,还需要存储矩阵的行数、列数以及非 0 元素的个数,另外,还需要将各结点链接成的链表存储在数组中。所以,采用结构体自定义十字链表的结构,为:
typedef struct
{
OLink *rhead,*chead; //存放各行和列链表头指针的数组
int mu,nu,tu; //矩阵的行数,列数和非零元的个数
}CrossList;
十字链表存储矩阵三元组
由于三元组存储的是该数据元素的行标、列标和数值,所以,通过行标和列标,就能在十字链表中唯一确定一个位置。首先判断该数据元素 A(例如三元组为:(i,j,k))所在行的具体位置:判断方法为:在同一行中通过列标来判断位置;在同一列中通过行标来判断位置。
- 如果 A 的列标 j 值比该行第一个非 0 元素 B 的 j 值小,说明该数据元素在元素 B 的左侧,这时 A 就成为了该行第一个非0元素(也适用于当该行没有非 0 元素的情况,可以一并讨论)
- 如果 A 的列标 j 比该行第一个非 0 元素 B 的 j 值大,说明 A 在 B 的右侧,这时,就需要遍历该行链表,找到插入位置的前一个结点,进行插入。
对应行链表的位置确定之后,判断数据元素 A 在对应列的位置:
- 如果 A 的行标比该列第一个非 0 元素 B 的行标 i 值还小,说明 A 在 B 的上边,这时 A 就成了该列第一个非 0 元素。(也适用于该列没有非 0 元素的情况)
- 反之,说明 A 在 B 的下边,这时就需要遍历该列链表,找到要插入位置的上一个数据元素,进行插入。
实现代码:
//创建系数矩阵M,采用十字链表存储表示
CrossList CreateMatrix_OL(CrossList M)
{
int m,n,t;
int i,j,e;
OLNode *p,*q;//定义辅助变量
scanf("%d%d%d",&m,&n,&t); //输入矩阵的行列及非零元的数量
//初始化矩阵的行列及非零元的数量
M.mu=m;
M.nu=n;
M.tu=t;
if(!(M.rhead=(OLink*)malloc((m+1)*sizeof(OLink)))||!(M.chead=(OLink*)malloc((n+1)*sizeof(OLink))))
{
printf("初始化矩阵失败");
exit(0); //初始化矩阵的行列链表
}
for(i=1;i<=m;i++)
{
M.rhead[i]=NULL; //初始化行
}
for(j=1;j<=n;j++)
{
M.chead[j]=NULL; //初始化列
}
for(scanf("%d%d%d",&i,&j,&e);0!=i;scanf("%d%d%d",&i,&j,&e)) //输入三元组 直到行为0结束
{
if(!(p=(OLNode*)malloc(sizeof(OLNode))))
{
printf("初始化三元组失败");
exit(0); //动态生成p
}
p->i=i;
p->j=j;
p->e=e; //初始化p
if(NULL==M.rhead[i]||M.rhead[i]->j>j)
{
p->right=M.rhead[i];
M.rhead[i]=p;
}
else
{
for(q=M.rhead[i];(q->right)&&q->right->j<j;q=q->right);
p->right=q->right;
q->right=p;
}
if(NULL==M.chead[j]||M.chead[j]->i>i)
{
p->down=M.chead[j];
M.chead[j]=p;
}
else
{
for (q=M.chead[j];(q->down)&& q->down->i<i;q=q->down);
p->down=q->down;
q->down=p;
}
}
return M;
}
十字链表解决矩阵相加问题
在解决 “将矩阵 B 加到矩阵 A ” 的问题时,由于采用的是十字链表法存储矩阵的三元组,所以在相加的过程中,针对矩阵 B 中每一个非 0 元素,需要判断在矩阵 A 中相对应的位置,有三种情况:- 提取到的 B 中的三元组在 A 相应位置上没有非 0 元素,此时直接加到矩阵 A 该行链表的对应位置上;
- 提取到的 B 中三元组在 A 相应位置上有非 0 元素,且相加不为 0 ,此时只需要更改 A 中对应位置上的三元组的值即可;
- 提取到的 B 中三元组在 A 响应位置上有非 0 元素,但相加为 0 ,此时需要删除矩阵 A 中对应结点。
提示:算法中,只需要逐个提取矩阵 B 中的非 0 元素,然后判断矩阵 A 中对应位置上是否有非 0 元素,根据不同的情况,相应作出处理。
设指针 pa 和 pb 分别表示矩阵 A 和矩阵 B 中同一行中的结点( pb 和 pa 都是从两矩阵的第一行的第一个非0元素开始遍历),针对上面的三种情况,细分为 4 种处理过程(第一种情况下有两种不同情况):
- 当 pa 结点的列值 j > pb 结点的列值 j 或者 pa == NULL (说明矩阵 A 该行没有非 0 元素),两种情况下是一个结果,就是将 pb 结点插入到矩阵 A 中。
- 当 pa 结点的列值 j < pb 结点的列值 j ,说明此时 pb 指向的结点位置比较靠后,此时需要移动 pa 的位置,找到离 pb 位置最近的非 0 元素,然后在新的 pa 结点的位置后边插入;
- 当 pa 的列值 j == pb 的列值 j, 且两结点的值相加结果不为 0 ,只需要更改 pa 指向的结点的值即可;
- 当 pa 的列值 j == pb 的列值 j ,但是两结点的值相加结果为 0 ,就需要从矩阵 A 的十字链表中删除 pa 指向的结点。
实现代码:
CrossList AddSMatrix(CrossList M,CrossList N){
OLNode * pa,*pb;//新增的两个用于遍历两个矩阵的结点
OLink * hl=(OLink*)malloc(M.nu*sizeof(OLink));//用于存储当前遍历的行为止以上的区域每一个列的最后一个非0元素的位置。
OLNode * pre=NULL;//用于指向pa指针所在位置的此行的前一个结点
//遍历初期,首先要对hl数组进行初始化,指向每一列的第一个非0元素
for (int j=1; j<=M.nu; j++) {
hl[j]=M.chead[j];
}
//按照行进行遍历
for (int i=1; i<=M.mu; i++) {
//遍历每一行以前,都要pa指向矩阵M当前行的第一个非0元素;指针pb也是如此,只不过遍历对象为矩阵N
pa=M.rhead[i];
pb=N.rhead[i];
//当pb为NULL时,说明矩阵N的当前行的非0元素已经遍历完。
while (pb!=NULL) {
//创建一个新的结点,每次都要复制一个pb结点,但是两个指针域除外。(复制的目的就是排除指针域的干扰)
OLNode * p=(OLNode*)malloc(sizeof(OLNode));
p->i=pb->i;
p->j=pb->j;
p->e=pb->e;
p->down=NULL;
p->right=NULL;
//第一种情况
if (pa==NULL||pa->j>pb->j) {
//如果pre为NULL,说明矩阵M此行没有非0元素
if (pre==NULL) {
M.rhead[p->i]=p;
}else{//由于程序开始时pre肯定为NULL,所以,pre指向的是第一个p的位置,在后面的遍历过程中,p指向的位置是逐渐向后移动的,所有,pre肯定会在p的前边
pre->right=p;
}
p->right=pa;
pre=p;
//在链接好行链表之后,链接到对应列的列链表中的相应位置
if (!M.chead[p->j]||M.chead[p->j]->i>p->i) {
p->down=M.chead[p->j];
M.chead[p->j]=p;
}else{
p->down=hl[p->j]->down;
hl[p->j]->down=p;
}
//更新hl中的数据
hl[p->j]=p;
}else{
//第二种情况,只需要移动pa的位置,继续判断pa和pb的位置,一定要有continue
if (pa->j<pb->j) {
pre=pa;
pa=pa->right;
continue;
}
//第三、四种情况,当行标和列标都想等的情况下,需要讨论两者相加的值的问题
if (pa->j==pb->j) {
pa->e+=pb->e;
//如果为0,摘除当前结点,并释放所占的空间
if (pa->e==0) {
if (pre==NULL) {
M.rhead[pa->i]=pa->right;
}else{
pre->right=pa->right;
}
p=pa;
pa=pa->right;
if (M.chead[p->j]==p) {
M.chead[p->j]=hl[p->j]=p->down;
}else{
hl[p->j]->down=p->down;
}
free(p);
}
}
}
pb=pb->right;
}
}
//用于输出矩阵三元组的功能函数
display(M);
return M;
}
完整代码演示
#include<stdio.h>
#include<stdlib.h>
typedef struct OLNode
{
int i,j,e; //矩阵三元组i代表行 j代表列 e代表当前位置的数据
struct OLNode *right,*down; //指针域 右指针 下指针
}OLNode,*OLink;
typedef struct
{
OLink *rhead,*chead; //行和列链表头指针
int mu,nu,tu; //矩阵的行数,列数和非零元的个数
}CrossList;
CrossList CreateMatrix_OL(CrossList M);
CrossList AddSMatrix(CrossList M,CrossList N);
void display(CrossList M);
void main()
{
CrossList M,N;
printf("输入测试矩阵M:\n");
M=CreateMatrix_OL(M);
printf("输入测试矩阵N:\n");
N=CreateMatrix_OL(N);
M=AddSMatrix(M,N);
printf("矩阵相加的结果为:\n");
display(M);
}
CrossList CreateMatrix_OL(CrossList M)
{
int m,n,t;
int i,j,e;
OLNode *p,*q;
scanf("%d%d%d",&m,&n,&t);
M.mu=m;
M.nu=n;
M.tu=t;
if(!(M.rhead=(OLink*)malloc((m+1)*sizeof(OLink)))||!(M.chead=(OLink*)malloc((n+1)*sizeof(OLink))))
{
printf("初始化矩阵失败");
exit(0);
}
for(i=1;i<=m;i++)
{
M.rhead[i]=NULL;
}
for(j=1;j<=n;j++)
{
M.chead[j]=NULL;
}
for(scanf("%d%d%d",&i,&j,&e);0!=i;scanf("%d%d%d",&i,&j,&e)) {
if(!(p=(OLNode*)malloc(sizeof(OLNode))))
{
printf("初始化三元组失败");
exit(0);
}
p->i=i;
p->j=j;
p->e=e;
if(NULL==M.rhead[i]||M.rhead[i]->j>j)
{
p->right=M.rhead[i];
M.rhead[i]=p;
}
else
{
for(q=M.rhead[i];(q->right)&&q->right->j<j;q=q->right);
p->right=q->right;
q->right=p;
}
if(NULL==M.chead[j]||M.chead[j]->i>i)
{
p->down=M.chead[j];
M.chead[j]=p;
}
else
{
for (q=M.chead[j];(q->down)&& q->down->i<i;q=q->down);
p->down=q->down;
q->down=p;
}
}
return M;
}
CrossList AddSMatrix(CrossList M,CrossList N){
OLNode * pa,*pb;
OLink * hl=(OLink*)malloc(M.nu*sizeof(OLink));
OLNode * pre=NULL;
for (int j=1; j<=M.nu; j++) {
hl[j]=M.chead[j];
}
for (int i=1; i<=M.mu; i++) {
pa=M.rhead[i];
pb=N.rhead[i];
while (pb!=NULL) {
OLNode * p=(OLNode*)malloc(sizeof(OLNode));
p->i=pb->i;
p->j=pb->j;
p->e=pb->e;
p->down=NULL;
p->right=NULL;
if (pa==NULL||pa->j>pb->j) {
if (pre==NULL) {
M.rhead[p->i]=p;
}else{
pre->right=p;
}
p->right=pa;
pre=p;
if (!M.chead[p->j]||M.chead[p->j]->i>p->i) {
p->down=M.chead[p->j];
M.chead[p->j]=p;
}else{
p->down=hl[p->j]->down;
hl[p->j]->down=p;
}
hl[p->j]=p;
}else{
if (pa->j<pb->j) {
pre=pa;
pa=pa->right;
continue;
}
if (pa->j==pb->j) {
pa->e+=pb->e;
if (pa->e==0) {
if (pre==NULL) {
M.rhead[pa->i]=pa->right;
}else{
pre->right=pa->right;
}
p=pa;
pa=pa->right;
if (M.chead[p->j]==p) {
M.chead[p->j]=hl[p->j]=p->down;
}else{
hl[p->j]->down=p->down;
}
free(p);
}
}
}
pb=pb->right;
}
}
display(M);
return M;
}
void display(CrossList M){
printf("输出测试矩阵:\n");
printf("M:\n---------------------\ni\tj\te\n---------------------\n");
for (int i=1;i<=M.nu;i++)
{
if (NULL!=M.chead[i])
{
OLink p=M.chead[i];
while (NULL!=p)
{
printf("%d\t%d\t%d\n",p->i,p->j,p->e);
p=p->down;
}
}
}
}
运行结果:
输入测试矩阵M:
3 3 3
1 2 1
2 1 1
3 3 1
0 0 0
输入测试矩阵N:
3 3 4
1 2 -1
1 3 1
2 3 1
3 1 1
0 0 0
矩阵相加的结果为:
输出测试矩阵:
M:
---------------------
i j e
---------------------
2 1 1
3 1 1
1 3 1
2 3 1
3 3 1
3 3 3
1 2 1
2 1 1
3 3 1
0 0 0
输入测试矩阵N:
3 3 4
1 2 -1
1 3 1
2 3 1
3 1 1
0 0 0
矩阵相加的结果为:
输出测试矩阵:
M:
---------------------
i j e
---------------------
2 1 1
3 1 1
1 3 1
2 3 1
3 3 1
总结
使用十字链表法解决稀疏矩阵的压缩存储的同时,在解决矩阵相加的问题中,对于某个单独的结点来说,算法的时间复杂度为一个常数(全部为选择结构),算法的整体的时间复杂度取决于两矩阵中非0元素的个数。声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: