作者:解学武
链表逆置,链表反转,链表翻转(带源码和解析)


链表翻转,简单地理解,就是将链表的头部结点变为链表的尾部结点,与此同时将原链表的尾部结点变成头部结点。如下图所示:
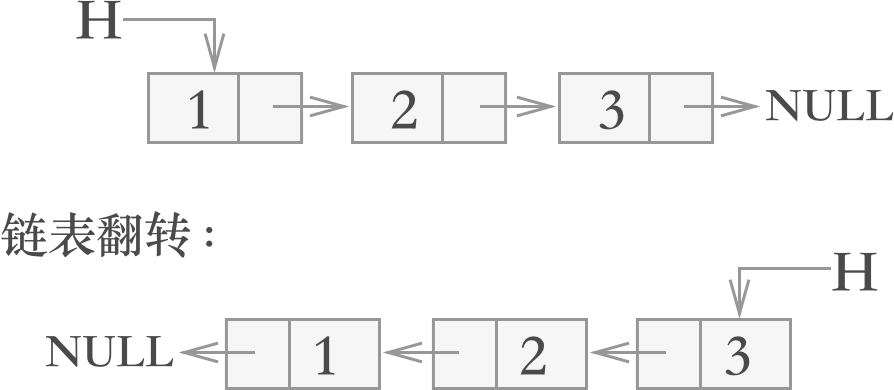
唯一比较特殊的是,链表中的首元结点(第一个结点)前面没有结点,所以在改变其指针指向的时候,要将其指针指向 NULL。
首先设置一个新的链表,用于接收旧链表上的结点,该新链表初始状态为一个空链表,如下图所示:
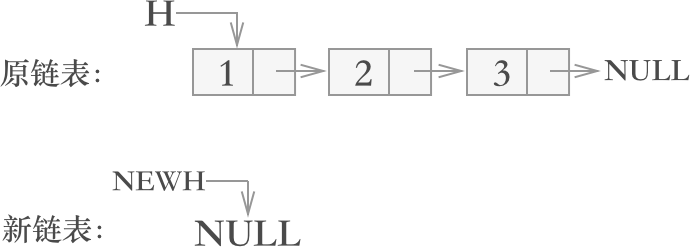
图 2 链表翻转过程一
遍历原链表,将结点依次插入到新链表的头部。要完成这一步操作,我们需要新添加两个指针(分别命名为 P 和 temp):
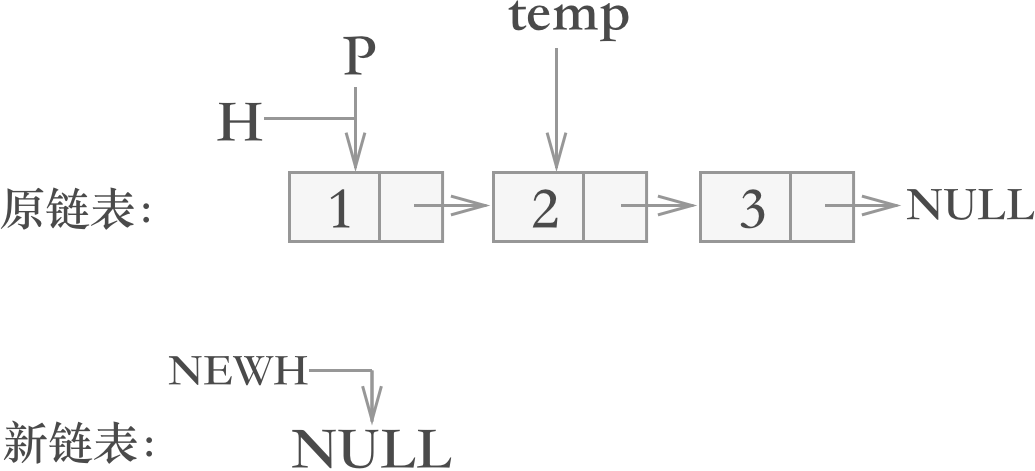
图 3 链表翻转过程二
以上的准备工作完成,链表的翻转就可以开始了。在遍历原链表的过程中,对每个结点都做如下操作:
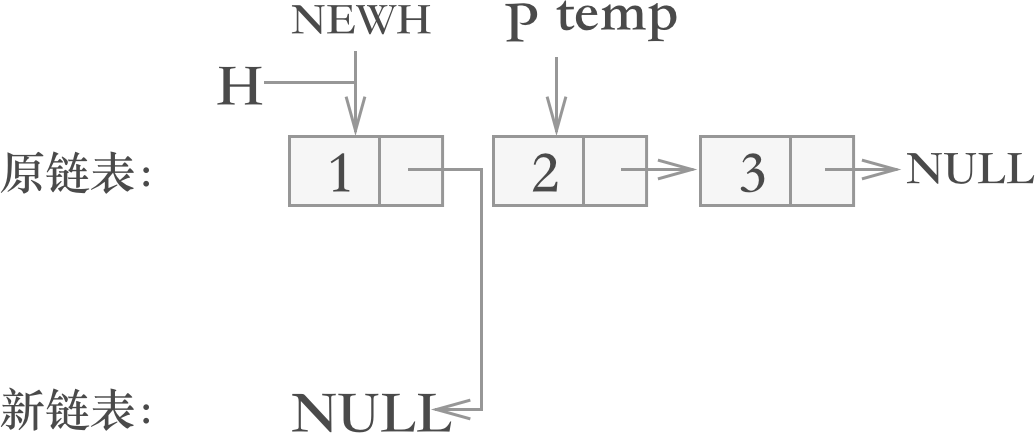
图 4 翻转结点 1
翻转结点 2,则上图经过 4 步调整后,变为下图:
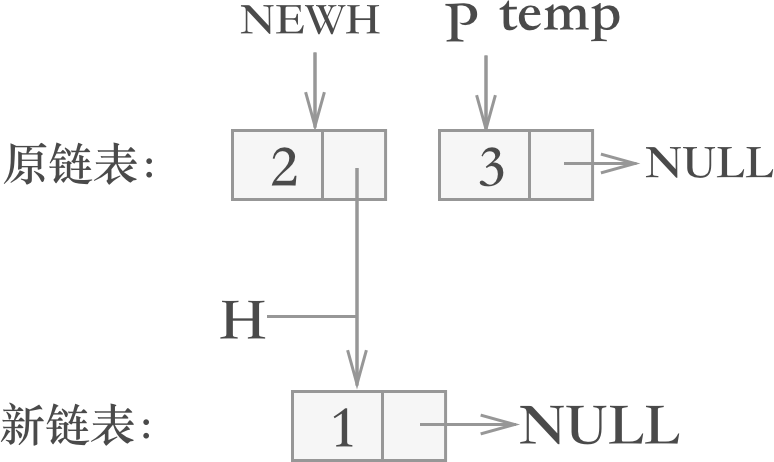
图 5 翻转结点 2
翻转结点 3 时,则上图经过 4 步调整后,变为下图:
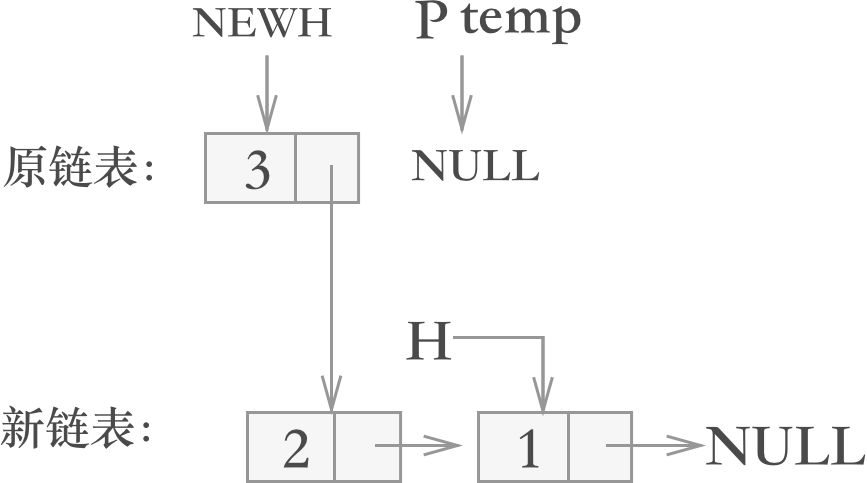
图 6 翻转结点 3
当翻转完最后一个结点 3 之后,由于指针 P 指向的为 NULL ,说明没有结点可以翻转,即遍历结束。(指针 P 为NULL ,为遍历结束的判断条件)。
通过对各个结点做如上的操作,当遍历结束,以 NEWH 指针作为头指针的链接即为翻转后的链表。
方法一的实现函数代码为:
方法一是依次遍历链表,更改每个结点的指向,最后一个结点为翻转链表的头部结点。而方法二则完全倒过来,其实现过程为:先通过递归的思维找到链表的头部,然后再改变每个结点的指向,最终到达链表翻转的目的。
方法二的代码实现函数为:
4-6行:对于给定的指针 H ,首先判断指针 H 是否存在,如果指针 H 不存在,或者指针 H 只含有一个结点,则直接返回,即指针 H 不需要翻转;
第 8 行:函数体内调用自身,是典型的递归。通过不断查找指针 H 所指结点的下一个结点,最终会找到链表的最后一个结点作为函数的返回值,而此结点恰恰就是翻转后链表的首元结点(第一个结点),所以我们用一个新指针 newH 来充当新链表的头指针。
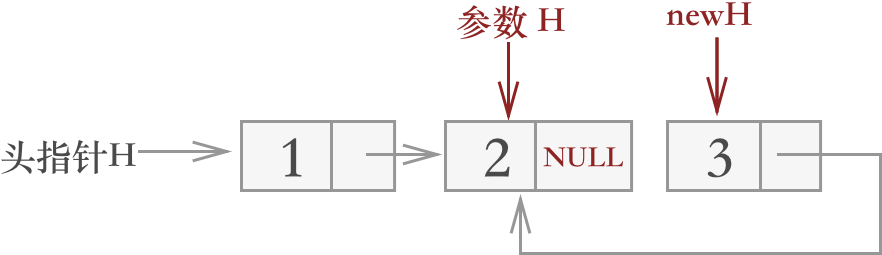
当通过递归找到对应的 newH 结点时,相应地,参数指针 H 也被递归至 newH 所指结点的上一结点处,如下图所示:

图 7 递归结束时的示意图
自图 7 开始,在指针 H 第一次返回时,此部分的代码运行示意图为:
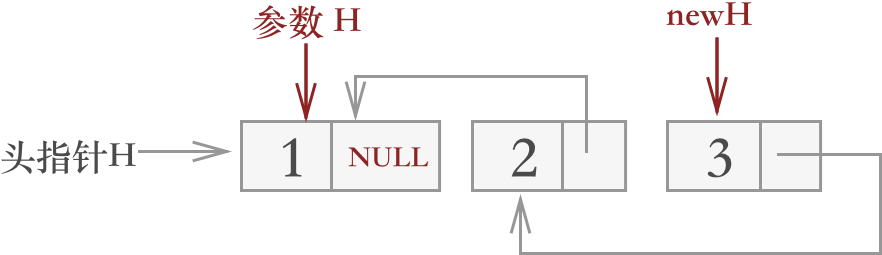
 指针 H 再次返回时,此部分的代码运行示意图为:
指针 H 再次返回时,此部分的代码运行示意图为:
 最终完成了链表的翻转,函数返回新链表的头指针 newH 。
最终完成了链表的翻转,函数返回新链表的头指针 newH 。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
图 1 链表翻转示意图
将链表进行翻转的方法有多种,本节给大家介绍两种实现方法。提示:H 为头指针,图示中的链表无头结点,头指针直接指向首元结点。
方法一
实现链表翻转最直接的方法就是:从链表的头部开始遍历每个结点,改变每个结点的指向,即将原本指向下一个结点的指针改为指向上一个结点。唯一比较特殊的是,链表中的首元结点(第一个结点)前面没有结点,所以在改变其指针指向的时候,要将其指针指向 NULL。
具体实现过程为:提示:原链表中的首元结点经过翻转后,会变为新链表的最后一个结点,所以其指针自然要指向 NULL。
首先设置一个新的链表,用于接收旧链表上的结点,该新链表初始状态为一个空链表,如下图所示:
图 2 链表翻转过程一
遍历原链表,将结点依次插入到新链表的头部。要完成这一步操作,我们需要新添加两个指针(分别命名为 P 和 temp):
- P 指针用于遍历链表,并将遍历到的结点插入到新链表中;
- temp 指针永远指向指针 P 所在结点的下一个结点,充当原链表在每次移除头部结点后的新头指针;
新添加指针 P 和 temp 后的链表,如下图所示:注意:使用头指针 H 遍历也可行(因为翻转完成后,旧链表旧不存在了),但是不建议大家这么做,对头指针的使用,大家要养成良好的习惯,避免头指针的滥用。
图 3 链表翻转过程二
以上的准备工作完成,链表的翻转就可以开始了。在遍历原链表的过程中,对每个结点都做如下操作:
- 将temp 移动至指针 p 所指结点的下一个结点,即 temp = P->next;
- 将该结点插入到新链表的头部,即 p->next=NEWH;
- 令指针 NEWH 指向该结点(即指针 p 指向的结点),即令 NEWH = p;
- 令指针 P 指向 temp 指针指向的位置,即 P= temp;
遍历每个结点的过程示意图如下:注意:第一步必须要在第四步的前面,否则会导致最终temp指向 NULL 的next,发生错误。
翻转结点 1 ,则图 3 经过以上 4 步调整后,变为:
图 4 翻转结点 1
翻转结点 2,则上图经过 4 步调整后,变为下图:
图 5 翻转结点 2
翻转结点 3 时,则上图经过 4 步调整后,变为下图:
图 6 翻转结点 3
当翻转完最后一个结点 3 之后,由于指针 P 指向的为 NULL ,说明没有结点可以翻转,即遍历结束。(指针 P 为NULL ,为遍历结束的判断条件)。
通过对各个结点做如上的操作,当遍历结束,以 NEWH 指针作为头指针的链接即为翻转后的链表。
方法一的实现函数代码为:
link *reverselink(link * H){
//判断链表 H 是否存在
if(H == NULL || H->next == NULL){
return H;
}
//创建指针 P 作为遍历链表的指针
link * p = H;
//创建一个新的链表,用于存储翻转链表,只不过该链表初始状态为NULL
link * newH = NULL;
//遍历指针 P 为 NULL 作为遍历结束的标志
while(p != NULL){
//第 1 步实现的代码
link *temp = p->next;
//第 2 步
p->next = newH;
//第 3 步
newH = p;
//第 4 步
p = temp;
}
return newH;
}
方法二
另一种方法较前一种比较复杂,需要使用到递归的思想。方法一是依次遍历链表,更改每个结点的指向,最后一个结点为翻转链表的头部结点。而方法二则完全倒过来,其实现过程为:先通过递归的思维找到链表的头部,然后再改变每个结点的指向,最终到达链表翻转的目的。
方法二的代码实现函数为:
//链表翻转的函数
link *reverseList(link * H){
//如果指针 H 是否存在
if(H == NULL || H->next == NULL){
return H;
}
//递归查找新链表的头,找到用赋值给 newH
link * newH=reverseList(H->next);
//递归完成后,H 初始状态为 NewH 的上一个结点。
//在一步步弹栈的过程中,始终另 H 指向的结点作为新链表的最后一个结点
H->next->next=H;
//在链接到新链表之后,要割去 H 所指结点与下一结点的联系,否则会使新链表产生环
H->next=NULL;
//返回新链表所指头部的指针。
return newH;
}
代码运行过程分析:4-6行:对于给定的指针 H ,首先判断指针 H 是否存在,如果指针 H 不存在,或者指针 H 只含有一个结点,则直接返回,即指针 H 不需要翻转;
第 8 行:函数体内调用自身,是典型的递归。通过不断查找指针 H 所指结点的下一个结点,最终会找到链表的最后一个结点作为函数的返回值,而此结点恰恰就是翻转后链表的首元结点(第一个结点),所以我们用一个新指针 newH 来充当新链表的头指针。
当通过递归找到对应的 newH 结点时,相应地,参数指针 H 也被递归至 newH 所指结点的上一结点处,如下图所示:
图 7 递归结束时的示意图
第 11行到最后:此部分代码为指针 H 逐层返回时才会运行的代码,在逐层返回的过程中,通过不断地将H所指结点赋值给 H->next->next,并且每次赋值结束后,都取消 H 所指结点的指向,最终达到翻转链表的目的。注意:头指针 H 和参数指针 H 完全不是一码事,作用域不同:参数 H 只在函数体内有效,而头指针 H 为主函数中声明。
自图 7 开始,在指针 H 第一次返回时,此部分的代码运行示意图为:
本节完整代码
#include <stdio.h>
#include <stdlib.h>
typedef struct Link{
//数据域
int count;
//指针域
struct Link * next;
}link;
link * initLink(){
//存储的数据,根据数据的特点,创建适当的数组
int element[3]={1,2,3};
//创建首元结点
link * head=(link*)malloc(sizeof(link));
head->count=element[0];
//for循环中需要一个指针temp,从头结点开始依次链接新创建的结点
link * temp=head;
//for循环逐个创建链表,并用temp两两链接
for (int i=1; i<3; i++) {
//循环创建结点
link *a=(link*)malloc(sizeof(link));
//初始化结点
a->count = element[i];
a->next=NULL;
//另指针 temp 每次循环都链接新的结点,并随后指向该结点
temp->next=a;
temp=temp->next;
}
return head;
}
//方法一实现链表翻转
link *reverselink(link * H){
//判断链表 H 是否存在
if(H == NULL || H->next == NULL){
return H;
}
//创建指针 P 作为遍历链表的指针
link * p = H;
//创建一个新的链表,用于存储翻转链表,只不过该链表初始状态为NULL
link * newH = NULL;
//遍历指针 P 为 NULL 作为遍历结束的标志
while(p != NULL){
//第 1 步实现的代码
link *temp = p->next;
//第 2 步
p->next = newH;
//第 3 步
newH = p;
//第 4 步
p = temp;
}
return newH;
}
//方法二实现链表翻转
link *reverseList(link * H){
//如果指针 H 是否存在
if(H == NULL || H->next == NULL){
return H;
}
//递归查找新链表的头,找到用赋值给 newH
link * newH=reverseList(H->next);
//递归完成后,H 初始状态为 NewH 的上一个结点。
//在一步步弹栈的过程中,始终另 H 指向的结点作为新链表的最后一个结点
H->next->next=H;
//在链接到新链表之后,要割去 H 所指结点与下一结点的联系,否则会使新链表产生环
H->next=NULL;
//返回新链表所指头部的指针。
return newH;
}
//遍历链表的输出函数
void display(link * H){
while(H){
printf("%d",H->count);
H=H->next;
}
printf("\n");
}
int main ()
{
//初始化链表
link * H = initLink();
display(H);
//使用方法一对链表 H 进行翻转
link * dnewH = reverselink(H);
display(dnewH);
//使用方法二对链表 dnewH 进行再次翻转
link * newH = reverseList(dnewH);
display(newH);
return 0;
}
运行结果:
123
321
123
321
123
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: