队列(queue)及其存储结构和特点详解


什么是队列?队列就是一个队伍。队列和栈一样,由一段连续的存储空间组成,是一个具有自身特殊规则的数据结构。我们说栈是后进先出的规则,队列刚好与之相反,是一个先进先出(FIFO,First In First Out)或者说后进后出(LILO,Last In Last Out)的数据结构。想象一下,在排队时是不是先来的就会先从队伍中出去呢?
队列是一种受限的数据结构,插入操作只能从一端操作,这一端叫作队尾;而移除操作也只能从另一端操作,这一端叫作队头。针对上面购买奶茶队伍的例子,排在收银员一端的就是队头,而新来的人则要排到队尾。
我们将没有元素的队列称为空队,也就是在没人要购买奶茶时,就没人排队了。往队列中插入元素的操作叫作入队,相应地,从队列中移除元素的操作叫作出队。
一般而言,队列的实现有两种方式:数组和链表。这里又提到了链表,我们暂时先不做讲解。用数组实现队列有两种方式,一种是顺序队列,一种是循环队列。这两种队列的存储结构及特点在之后进行介绍。
用数组实现队列,若出现队列满了的情况,则这时就算有新的元素需要入队,也没有位置。此时一般的选择是要么丢掉,要么等待,等待的时间一般会有程序控制。
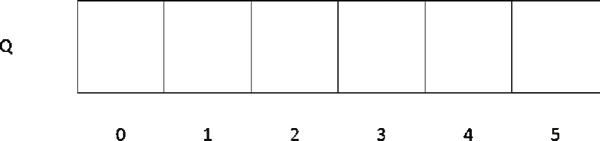
图 1 顺序队列的存储结构
顺序队列会有两个标记,一个是队头位置(head),一个是下一个元素可以插入的队尾位置(tail)。一开始两个标记都指向数组下标为 0 的位置,如图 2 所示。
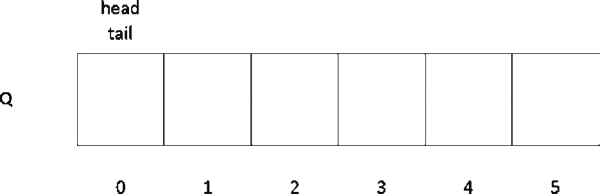
图 2 顺序队列的初始情况
在插入元素之后,tail 标记就会加1,比如入队三个元素,分别为 A、B、C,则当前标记及存储情况如图 3 所示。
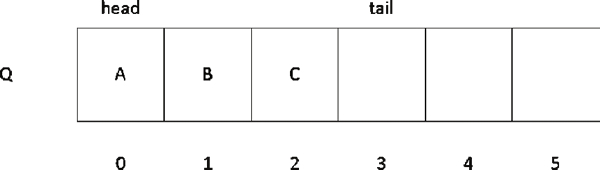
图 3 顺序队列入队三个元素的存储情况
当前 head 为 0 时,tail 为 3。接下来进行出队操作,出队一个元素,head 指向的位置则加 1。比如进行一次出队操作之后,顺序队列的存储情况如图 4 所示。
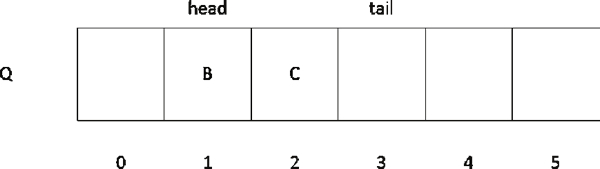
图 4 顺序队列出队一个元素之后的存储情况
因此,在顺序队列中,队列中元素的个数我们可以用 tail 减去 head 计算。当 head 与 tail 相等时,队列为空队,当 tail 达到数组长度,也就是队列存储之外的位置时,说明这个队列已经无法再容纳其他元素入队了。空间是否都满了?并没有,由于两个标记都是只增不减,所以两个标记最终都会到数组的最后一个元素之外,这时虽然数组是空的,但也无法再往队列里加入元素了。
当队列中无法再加入元素时,我们称之为“上溢”;当顺序队列还有空间却无法入队时,我们称之为“假上溢”;如果空间真的满了,则我们称之为“真上溢”;如果队列是空的,则执行出队操作,这时队列里没有元素,不能出队,我们称之为“下溢”,就像奶茶店根本没人排队,收银员也就没法给别人开出消费单了。
怎么解决顺序队列的“假上溢”问题呢?这时就需要采用循环队列了。
当顺序队列出现假上溢时,其实数组前端还有空间,我们可以不用把标记指向数组外的地方,只需要把这个标记重新指向开始处就能解决。想象一下这个数组首尾相接,成为一个圈。存储结构还是之前提到的,在一个数组上。此时,如果当前队列中元素的情况如图 5 所示:

图 5 当 tail 超出数组位置时,会被重新标记为 0
那么在入队 E、F 元素时,存储结构会如图 6 所示。
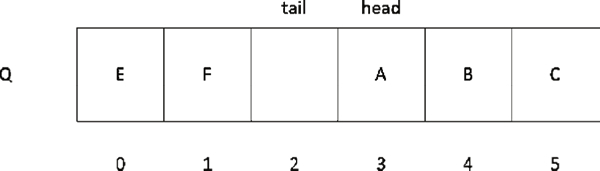
图 6 继续入队 E、F 元素
一般而言。我们在对 head 或者 tail 加 1 时,为了方便,可直接对结果取余数组长度,得到我们需要的数组长度。另外由于顺序队列存在“假上溢”的问题,所以在实际使用过程中都是使用循环队列来实现的。
但是循环队列中会出现这样一种情况:当队列没有元素时,head 等于 tail,而当队列满了时,head 也等于 tail。为了区分这两种状态,一般在循环队列中规定队列的长度只能为数组总长度减 1,即有一个位置不放元素。因此,当 head 等于 tail 时,说明队列为空队,而当 head 等于(tail+1)%length 时(length 为数组长度),说明队满。
下面为顺序列队的代码实现:
这就出现了抢购手机时,抢购界面稍后才告诉我们抢购结果的情况。我有个朋友在抢购成功之后,抢购界面提示他稍后去订单中查看结果,当下查看订单却没有发现新订单,其实是因为他的请求已经进入了服务器处理的队列,服务器处理完之后才会为他生成订单。
这时参考奶茶店的例子,每个购买奶茶的人就是一个生产者,依次进入第 1 个队列中,收银员就是一个消费者(假设这个收银员称为消费者 A),负责“消费”队列中的购买者,让购买者逐个从队列中出来。通过提供给购买者带有编号的一张小票,让购买者进入了第 2 个队列。此时收银员在第 2 个队列中又作为生产者出现。
第 2 个队列的消费者是谁?是制作奶茶的店员,这里称之为消费者 B。而一般规模较大的奶茶店,制作奶茶的店员会较多,假设有两人以上,即消费者 B 比消费者 A 多。此时第 2 个队列就起到了缓冲的作用,达到了平衡的效果。排队付款一般较快,等待制作奶茶一般较慢,因此需要安排较多的制作奶茶的店员。
因此对于生产者和消费者的设计模式来说,有一点非常重要,那就是生产的速度要和消费的速度持平。如果生产得太快,而消费得太慢,那么队列会很长。而对于计算机来说,队列太长所占用的空间也会较大。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
队列是一种受限的数据结构,插入操作只能从一端操作,这一端叫作队尾;而移除操作也只能从另一端操作,这一端叫作队头。针对上面购买奶茶队伍的例子,排在收银员一端的就是队头,而新来的人则要排到队尾。
我们将没有元素的队列称为空队,也就是在没人要购买奶茶时,就没人排队了。往队列中插入元素的操作叫作入队,相应地,从队列中移除元素的操作叫作出队。
一般而言,队列的实现有两种方式:数组和链表。这里又提到了链表,我们暂时先不做讲解。用数组实现队列有两种方式,一种是顺序队列,一种是循环队列。这两种队列的存储结构及特点在之后进行介绍。
用数组实现队列,若出现队列满了的情况,则这时就算有新的元素需要入队,也没有位置。此时一般的选择是要么丢掉,要么等待,等待的时间一般会有程序控制。
队列的存储结构
顺序队列的存储结构如图 1 所示。图 1 顺序队列的存储结构
顺序队列会有两个标记,一个是队头位置(head),一个是下一个元素可以插入的队尾位置(tail)。一开始两个标记都指向数组下标为 0 的位置,如图 2 所示。
图 2 顺序队列的初始情况
在插入元素之后,tail 标记就会加1,比如入队三个元素,分别为 A、B、C,则当前标记及存储情况如图 3 所示。
图 3 顺序队列入队三个元素的存储情况
当前 head 为 0 时,tail 为 3。接下来进行出队操作,出队一个元素,head 指向的位置则加 1。比如进行一次出队操作之后,顺序队列的存储情况如图 4 所示。
图 4 顺序队列出队一个元素之后的存储情况
因此,在顺序队列中,队列中元素的个数我们可以用 tail 减去 head 计算。当 head 与 tail 相等时,队列为空队,当 tail 达到数组长度,也就是队列存储之外的位置时,说明这个队列已经无法再容纳其他元素入队了。空间是否都满了?并没有,由于两个标记都是只增不减,所以两个标记最终都会到数组的最后一个元素之外,这时虽然数组是空的,但也无法再往队列里加入元素了。
当队列中无法再加入元素时,我们称之为“上溢”;当顺序队列还有空间却无法入队时,我们称之为“假上溢”;如果空间真的满了,则我们称之为“真上溢”;如果队列是空的,则执行出队操作,这时队列里没有元素,不能出队,我们称之为“下溢”,就像奶茶店根本没人排队,收银员也就没法给别人开出消费单了。
怎么解决顺序队列的“假上溢”问题呢?这时就需要采用循环队列了。
当顺序队列出现假上溢时,其实数组前端还有空间,我们可以不用把标记指向数组外的地方,只需要把这个标记重新指向开始处就能解决。想象一下这个数组首尾相接,成为一个圈。存储结构还是之前提到的,在一个数组上。此时,如果当前队列中元素的情况如图 5 所示:
图 5 当 tail 超出数组位置时,会被重新标记为 0
那么在入队 E、F 元素时,存储结构会如图 6 所示。
图 6 继续入队 E、F 元素
一般而言。我们在对 head 或者 tail 加 1 时,为了方便,可直接对结果取余数组长度,得到我们需要的数组长度。另外由于顺序队列存在“假上溢”的问题,所以在实际使用过程中都是使用循环队列来实现的。
但是循环队列中会出现这样一种情况:当队列没有元素时,head 等于 tail,而当队列满了时,head 也等于 tail。为了区分这两种状态,一般在循环队列中规定队列的长度只能为数组总长度减 1,即有一个位置不放元素。因此,当 head 等于 tail 时,说明队列为空队,而当 head 等于(tail+1)%length 时(length 为数组长度),说明队满。
下面为顺序列队的代码实现:
package me.irfen.algorithm.ch02;
public class ArrayQueue {
private final Object[] items;
private int head = 0;
private int tail = 0;
/**
* 初始化队列
* @param capacity 队列长度
*/
public ArrayQueue(int capacity) {
this.items = new Object[capacity];
}
/**
* 入队
* @param item
* @return
*/
public boolean put(Object item) {
if (head == (tail + 1) % items.length) {
// 说明队满
return false;
}
items[tail] = item;
tail = (tail + 1) % items.length; // tail标记向后移动一位
return true;
}
/**
* 获取队列头元素,不出队
* @return
*/
public Object peek() {
if (head == tail) {
// 说明队空
return null;
}
return items[head];
}
/**
* 出队
* @return
*/
public Object poll() {
if (head == tail) {
// 说明队空
return null;
}
Object item = items[head];
items[head] = null; // 把没用的元素赋空值,当然不设置也可以,反正标记移动了,之后会被覆盖
head = (head + 1) % items.length; // head标记向后移动一位
return item;
}
public boolean isFull() {
return head == (tail + 1) % items.length;
}
public boolean isEmpty() {
return head == tail;
}
/**
* 队列元素数
* @return
*/
public int size() {
if (tail >= head) {
return tail - head;
} else {
return tail + items.length - head;
}
}
}
接下来通过测试代码验证前面代码的正确性:
package me.irfen.algorithm.ch02;
public class ArrayQueueTest {
public static void main(String[] args) {
ArrayQueue queue = new ArrayQueue(4);
System.out.println(queue.put("A")); // true
System.out.println(queue.put("B")); // true
System.out.println(queue.put("C")); // true
System.out.println(queue.put("D")); // false
System.out.println(queue.isFull());// true,当前队列已经满了,并且D元素没有入队成功
System.out.println(queue.size()); // 3,队列中有三个元素
System.out.println(queue.peek()); // A,获取队头元素,不出队
System.out.println(queue.poll()); // A
System.out.println(queue.poll()); // B
System.out.println(queue.poll()); // C
System.out.println(queue.isEmpty()); // true,当前队列为空队
}
}
在上面的代码中尽管声明的长度是 4,但是只能放入 3 个元素,这里是通过在初始化数组时多设置一个位置来解决问题的;也可以通过增加一个变量来记录元素的个数去解决问题,不需要两个标记去确定是队空还是队满,元素也能放满而不用空出一位了。队列的特点
队列的特点也是显而易见的,那就是先进先出。出队的一头是队头,入队的一头是队尾。当然,队列一般来说都会规定一个有限的长度,叫作队长(chang)。队列的适用场景
队列在实际开发中是很常用的。在一般程序中会将队列作为缓冲器或者解耦使用。下面举几个例子具体说明队列的用途。解耦,即当一个项目发展得比较大时,必不可少地要拆分各个模块。为了尽可能地让各个模块独立,则需要解耦,即我们常听说的高内聚、低耦合。如何对各模块进行解耦?其中一种方式就是通过消息队列。
1) 某品牌手机在线秒杀用到的队列
现在,某个品牌的手机推出新型号,想要购买就需要上网预约,到了开抢时间就得赶紧打开网页守着,疯狂地刷新页面,疯狂地点击抢购按钮。一般在每次秒杀中提供的手机只有几千部。假设有两百万人抢购,则从开抢的这一秒开始,两百万人都开始向服务器发送请求。如果服务器能直接处理请求,把抢购结果立刻告诉用户,同时为抢购成功的用户生成订单,让用户付款购买手机,则这对服务器的要求很高,很难实现。那么该怎么解决呢?解决方法是:在接收到每个请求之后,把这些请求按顺序放入队列的队尾中,然后提示用户“正在排队中……”,接下来用户开始排队;而在这个队列的另一端,也就是队头,会有一些服务器在处理,根据先后顺序告知用户抢购结果。这就出现了抢购手机时,抢购界面稍后才告诉我们抢购结果的情况。我有个朋友在抢购成功之后,抢购界面提示他稍后去订单中查看结果,当下查看订单却没有发现新订单,其实是因为他的请求已经进入了服务器处理的队列,服务器处理完之后才会为他生成订单。
注:这种方式也叫作异步处理。异步与同步是相对的。同步是在一个调用执行完成之后,等待调用结束返回;而异步不会立刻返回结果,返回结果的时间是不可预料的,在另一端的服务器处理完成之后才有结果,如何通知执行的结果又是另一回事。
2) 生产者和消费者模式
有个非常有名的设计模式,叫作生产者和消费者模式。这个设计模式就像有一个传送带,生产者在传送带这头将生产的货物放上去,消费者在另一头逐个地将货物从传送带上取下来。这个设计模式的实现原理也比较简单,即存在一个队列,若干个生产者同时向队列中添加元素,然后若干个消费者从队列中获取元素。这时参考奶茶店的例子,每个购买奶茶的人就是一个生产者,依次进入第 1 个队列中,收银员就是一个消费者(假设这个收银员称为消费者 A),负责“消费”队列中的购买者,让购买者逐个从队列中出来。通过提供给购买者带有编号的一张小票,让购买者进入了第 2 个队列。此时收银员在第 2 个队列中又作为生产者出现。
第 2 个队列的消费者是谁?是制作奶茶的店员,这里称之为消费者 B。而一般规模较大的奶茶店,制作奶茶的店员会较多,假设有两人以上,即消费者 B 比消费者 A 多。此时第 2 个队列就起到了缓冲的作用,达到了平衡的效果。排队付款一般较快,等待制作奶茶一般较慢,因此需要安排较多的制作奶茶的店员。
因此对于生产者和消费者的设计模式来说,有一点非常重要,那就是生产的速度要和消费的速度持平。如果生产得太快,而消费得太慢,那么队列会很长。而对于计算机来说,队列太长所占用的空间也会较大。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: