什么是重连通图


连通图中,如果任意两个顶点之间都存在不止一条通路,这样的图就称为重连通图。
举个简单的例子:
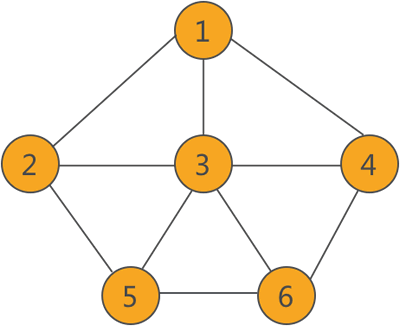
图 1 重连通图
图 1 不仅是连通图,还是重连通图,因为图中各个顶点之间存在不止一条通路,比如顶点 2 和 3 之间的通路有 2-3、2-5-3、2-1-3 等。
在重连通图中,删除某个顶点(包括连接该顶点的边)后并不会破坏整个图的连通性。例如删除图 1 中的顶点 3,图的连通性并不会被破坏。
对于给定的连通图,如果删除某个顶点后,整个图被分割成多个(≥2)连通分量,那么称该顶点为连通图的一个关结点(或者称“割点”)。
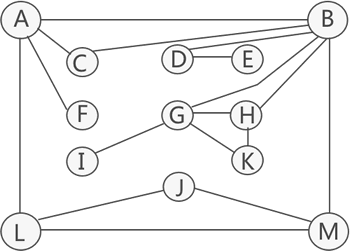
图 2 连通图
图 2 是一个连通图,但不是重连通图。图中有 4 个关结点,分别是:A、B、D 和 G。比如删除顶点 B 及相关联的边后,原图就变为:
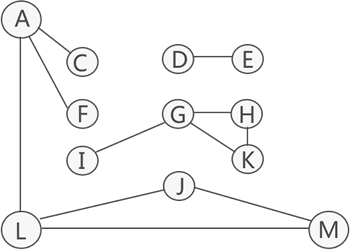
图 3 连通分量
可以看到,图被分割成 3 个连通分量,顶点集合分别是:{A、C、F、L、M、J}、{G、H、I、K} 和 {D、E}。删除一个顶点后,图的连通性被破坏,所以它不是重连通图。
了解了什么是关结点后,重连通图其实就是没有关结点的连通图。
小到城市之间,大到国家之间的航空网也可以看作是一个连通图,如果将它建设成为重连通图,当某条航线因为天气等因素关闭时,飞机仍可以从别的航线到达目的地。
在战争中,有“兵马未动,粮草先行”的说法,可见后勤补给对军队的重要性。如果补给线是一个重连通图,就不用过于担心补给线被破坏的问题,因为即使破坏一条,还有其它的,只要连通度足够大。
对于任意一个连通图来说,都可以通过深度优先搜索算法获得一棵深度优先生成树。例如,图 2 通过深度优先搜索获得的深度优先生成树为:
虚线表示遍历生成树时没有用到的边,简称“回边”。
在深度优先生成树中,某个结点的孩子结点是在该结点之后搜索到的结点,某个结点的父结点和通过回边连接的祖先结点都是在该结点之前搜索到的结点。
如果连通图中存在关结点,可能是树根结点,也可能是某个非叶子结点:
以图 4 的生成树为例,依次判断各个结点是否为关结点:
综上所述,图 3 中的关结点有 4 个,分别是: A 、 B 、 D 、 G 。因此图 3 仅仅是一个连通图,不是重连通图。
编码实现“在给定的连通图中查找关结点”,可以参考如下给出的完整 C 语言程序。
DFSArticul() 函数对各个非叶子结点是否为关结点进行了判断,实现过程中需要借助 visit 和 low 这两个数组:
以图 2 的连通图为例,程序执行完成时,visit 数组和 low 数组中记录的数据如下表所示:
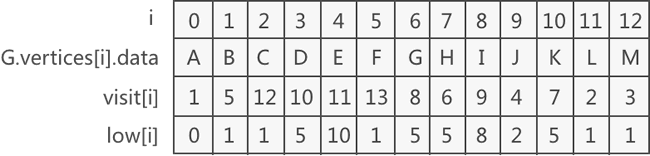
图 5 visit和low数组的功能
以 B 结点为例,通过 visit 数组得到它的访问序号是 5。B 有三棵子树,根结点分别是 H、D 和 C:
由于 B 的访问序号并不比所有孩子结点对应的 low 大,删除 B 结点会导致 H 子树和 D 子树分割出去,因此 B 结点是关结点。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
举个简单的例子:
图 1 重连通图
图 1 不仅是连通图,还是重连通图,因为图中各个顶点之间存在不止一条通路,比如顶点 2 和 3 之间的通路有 2-3、2-5-3、2-1-3 等。
在重连通图中,删除某个顶点(包括连接该顶点的边)后并不会破坏整个图的连通性。例如删除图 1 中的顶点 3,图的连通性并不会被破坏。
对于给定的连通图,如果删除某个顶点后,整个图被分割成多个(≥2)连通分量,那么称该顶点为连通图的一个关结点(或者称“割点”)。
图 2 连通图
图 3 连通分量
了解了什么是关结点后,重连通图其实就是没有关结点的连通图。
在重连通图中,如果一味地做删除操作,直到删除 K 个顶点后图的连通性才遭到破坏,则称此重连通图的连通度为 K 。
重连通图的实际应用
现如今,通信网络对人们的生活有着重要的影响,如果将通信网络比做一个巨大的连通图的话,它的连通度 K 值越高,证明其稳定性越好,即使某一个站点发生故障无法工作,也不会影响整个系统的正常工作。小到城市之间,大到国家之间的航空网也可以看作是一个连通图,如果将它建设成为重连通图,当某条航线因为天气等因素关闭时,飞机仍可以从别的航线到达目的地。
在战争中,有“兵马未动,粮草先行”的说法,可见后勤补给对军队的重要性。如果补给线是一个重连通图,就不用过于担心补给线被破坏的问题,因为即使破坏一条,还有其它的,只要连通度足够大。
重连通图的判断方法
了解了什么是重连通图之后,如何判断一个连通图是否为重连通图呢?对于任意一个连通图来说,都可以通过深度优先搜索算法获得一棵深度优先生成树。例如,图 2 通过深度优先搜索获得的深度优先生成树为:
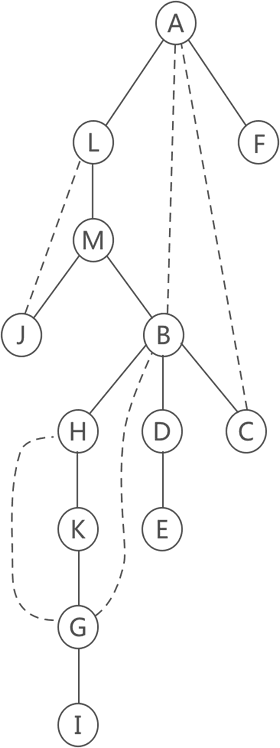
虚线表示遍历生成树时没有用到的边,简称“回边”。
在深度优先生成树中,某个结点的孩子结点是在该结点之后搜索到的结点,某个结点的父结点和通过回边连接的祖先结点都是在该结点之前搜索到的结点。
如果连通图中存在关结点,可能是树根结点,也可能是某个非叶子结点:
- 树根结点:如果树的根结点有多棵(≥2)子树,那么它一定是关结点,因为一旦树根被删除,生成树就会变成森林。
- 非叶子结点(用 V 表示):以 V 为根结点的树中可能有多棵子树,只要存在一颗子树,它的所有结点都没有回边连接着 V 的祖先结点,那么 V 就是一个关结点。因为一旦 V 被删除,那么 V 的子树就会从整棵树上分割出去。
以图 4 的生成树为例,依次判断各个结点是否为关结点:
- A:是整棵树的根结点,有两棵子树,所以 A 一定是关结点;
- L:只有一棵子树,树中的 B 和 C 结点都有回边连接着 L 的祖先结点(A 结点),所以 L 不是关结点;
- M:有两棵子树,左子树和右子树都有回边连接着 M 的祖先结点,所以 M 不是关结点;
- B:有三棵子树,左子树和中子树都没有回边连接 B 的祖先结点,所以 B 是关结点;
- D:只有一棵子树,树中没有回边连接 D 的祖先结点,所以 D 是关结点;
- H:只有一棵子树,树中有回边连接着 H 的祖先结点(B 结点),所以 H 不是关结点;
- K: 和 H 相同,K 结点只有一颗子树,树中有回边连接着 K 的祖先结点(B 结点),所以 K 不是关结点;
- G:只有一棵子树,树中不存在回边,所以 G 是关结点。
综上所述,图 3 中的关结点有 4 个,分别是: A 、 B 、 D 、 G 。因此图 3 仅仅是一个连通图,不是重连通图。
重连通图的具体实现
对于给定的连通图,如果在图中找不到关结点,那么此图是重连通图,反之就不是。编码实现“在给定的连通图中查找关结点”,可以参考如下给出的完整 C 语言程序。
#include<stdio.h>
#include<stdlib.h>
#define MAX_VERTEX_NUM 20 //最大顶点个数
#define VertexType char //图中顶点的类型
typedef enum { false, true }bool;
int visit[MAX_VERTEX_NUM] = { 0 };
int low[MAX_VERTEX_NUM] = { 0 };
int count = 1;
typedef struct ArcNode {
int adjvex; // 存储弧,即另一端顶点在数组中的下标
struct ArcNode* nextarc; // 指向下一个结点
}ArcNode;
typedef struct VNode {
VertexType data; //顶点的数据域
ArcNode* firstarc; //指向下一个结点
}VNode, AdjList[MAX_VERTEX_NUM]; //存储各链表首元结点的数组
typedef struct {
AdjList vertices; //存储图的邻接表
int vexnum, arcnum; //图中顶点数以及弧数
}ALGraph;
void CreateGraph(ALGraph* graph) {
int i, j;
char VA, VB;
int indexA, indexB;
ArcNode* node = NULL;
printf("输入顶点和边的数目:\n");
scanf("%d %d", &(graph->vexnum), &(graph->arcnum));
//清空缓冲区
scanf("%*[^\n]"); scanf("%*c");
printf("输入各个顶点的值:\n");
for (i = 0; i < graph->vexnum; i++) {
scanf("%c", &(graph->vertices[i].data));
getchar();
graph->vertices[i].firstarc = NULL;
}
printf("输入边的信息(a b 表示边 a-b):\n");
//输入弧的信息,并为弧建立结点,链接到对应的链表上
for (i = 0; i < graph->arcnum; i++) {
scanf("%c %c", &VA, &VB);
getchar();
//找到 VA 和 VB 在邻接表中的位置下标
for (j = 0; j < graph->vexnum; j++) {
if (graph->vertices[j].data == VA) {
indexA = j;
}
if (graph->vertices[j].data == VB) {
indexB = j;
}
}
//添加从 A 到 B 的弧
node = (ArcNode*)malloc(sizeof(ArcNode));
node->adjvex = indexB;
node->nextarc = graph->vertices[indexA].firstarc;
graph->vertices[indexA].firstarc = node;
//添加从 B 到 A 的弧
node = (ArcNode*)malloc(sizeof(ArcNode));
node->adjvex = indexA;
node->nextarc = graph->vertices[indexB].firstarc;
graph->vertices[indexB].firstarc = node;
}
}
//判断 G.vertices[v].data 是否为关结点
//函数执行结束时,会找到 v 结点(或其孩子结点)相连的祖先结点的访问次序号,如果有多个祖先结点,找到的是值最小的次序号,并存储在 low[v] 的位置
void DFSArticul(ALGraph G, int v) {
int min, w;
//假设当前结点不是关结点
bool isAritcul = false;
ArcNode* p = NULL;
//记录当前结点被访问的次序号
visit[v] = min = ++count;
//遍历每个和 v 相连的结点,有些是 v 的孩子结点,有些是祖先结点
for(p = G.vertices[v].firstarc; p ; p = p->nextarc)
{
w = p->adjvex;
//如果 visit[w] 的值为 0,表示 w 是 v 的孩子结点
if (visit[w] == 0)
{
//深度优先遍历,继续判断 w 是否为关结点,计算出 low[w] 的值
DFSArticul(G, w);
//如果 w 结点对应的 low 值比 min 值小,表明 w 与 v 的某个祖先结点建立着连接,用 min 变量记录下 low[w] 的值
if (low[w] < min) {
min = low[w];
}
// 如果 v 结点的访问次序号 <= 孩子结点记录的祖先结点的访问次序号,表明孩子结点并没有和 v 的祖宗结点建立连接,此时 v 就是关结点
if (visit[v] <= low[w]) {
// v 可能有多个孩子结点,visit[v] <= low[w] 条件可能成立多次。v 是关结点的信息只需要输出一次即可。
if (isAritcul == false) {
isAritcul = true;
printf("%c ", G.vertices[v].data);
}
}
}
//如果 w 之前访问过,表明 w 是 v 的祖先结点,直接更新 min 记录的次序号
else if(visit[w] < min)
{
min = visit[w];
}
}
//min 变量的值经过多次更新,最终记录的是和 v 结点(或其孩子结点)相连的祖先结点的访问次序号,如果有多个祖先结点,min 记录的是值最小的次序号
low[v] = min;
}
void FindArticul(ALGraph G) {
//以 G.vertices[0] 为深度优先生成树的树根
ArcNode* p = G.vertices[0].firstarc;
visit[0] = 1;
printf("关节点是:\n");
//从树根顶点的第一个孩子结点出发进行深度优先搜索,查找关结点
DFSArticul(G, p->adjvex);
//如果从第一个孩子结点点出发,不能遍历完所有的顶点,表明树根不止有一个孩子结点,树根就是关结点
if (count < G.vexnum) {
printf("%c ", G.vertices[0].data);
//继续判断别的子树,查找关结点
while (p->nextarc) {
p = p->nextarc;
if (visit[p->adjvex] == 0) {
DFSArticul(G, p->adjvex);
}
}
}
}
int main() {
ALGraph graph;
CreateGraph(&graph);
FindArticul(graph);
return 0;
}
程序中,存储连通图采用的是邻接表结构,查找关结点是在深度优先搜索的过程实现的。
程序中,FindArticul() 函数对树根结点是否为关结点进行了判断,实现方法是:从根结点的某个孩子结点出发进行深度优先搜索,如果无法搜索到图中的所有顶点,表明根结点有多个孩子结点,那么它就一定是关结点。注意,虽然程序中没有构建深度优先生成树,但深度优先搜索的过程中,顶点之间就具备父子、祖孙等关系。
DFSArticul() 函数对各个非叶子结点是否为关结点进行了判断,实现过程中需要借助 visit 和 low 这两个数组:
- visit 数组记录了图中每个顶点的访问次序,例如 A 顶点第 1 个访问、B 顶点第 2 个访问等。在深度优先生成树中,如果一个结点是另一个结点的祖先,那么深度优先搜索过程中最先访问的一定是祖先结点,也就是访问序号更小的那个结点。
- low 数组的功能是:除了树根结点和叶子结点外,在以各个结点为根的子树中,一定存在一条连接父结点的边,可能存在多条回边连接着当前结点的不同祖先结点,比较父结点和祖先结点的访问序号,去最小值(代表辈分最高的祖先结点)存储在 low 数组中。
判断某个非叶子结点(用 V 表示)是否为关结点的过程是:通过 visit 数组得到 V 的访问序号,从 low 数组中找到 V 各个孩子结点对应的值,如果 V 的访问序号比每个孩子结点对应的值都大,表明 V 的每棵子树都和 V 的祖先结点建立着连接,删除 V 并不会将它的子树分割出去,那么 V 就不是关结点;反之,只要有一个孩子结点对应的值比 V 的访问序号大,那么 V 一定是关结点。借助 visit 数组记录的访问序号,可以快速判断出结点间的辈分(谁的辈分更大);借助 low 数组,可以快速找到和某个子树连接的、辈分最高的祖先结点的访问序号。
以图 2 的连通图为例,程序执行完成时,visit 数组和 low 数组中记录的数据如下表所示:
图 5 visit和low数组的功能
以 B 结点为例,通过 visit 数组得到它的访问序号是 5。B 有三棵子树,根结点分别是 H、D 和 C:
- H 在 low 数组中对应的值是 5,表明在以 H 为根结点的子树中,连接的辈分最高的祖先结点是访问序号为 5 的 B 结点;
- D 在 low 数组中对应的值也是 5,表明在以 D 为跟结点的子树中,连接的辈分最高的祖先结点是访问序号为 5 的 B 结点;
- C 在 low 数组中对应的值是 1,表明在以 C 为根结点的子树中,连接的辈分最高的祖先结点是访问序号为 1 的 A 结点。
由于 B 的访问序号并不比所有孩子结点对应的 low 大,删除 B 结点会导致 H 子树和 D 子树分割出去,因此 B 结点是关结点。
以图 2 的连通图为例,程序的执行结果为:程序中第 93 行代码,只要有一个孩子结点对应的 low 值大于父亲节点的 visit 值,那么父亲节点就是一个关结点。
输入顶点和边的数目:
13 17
输入各个顶点的值:
A B C D E F G H I J K L M
输入边的信息(a b 表示边 a-b):
A B
A C
A F
A L
B C
B D
B G
B H
B M
D E
G H
G K
H K
G I
L J
L M
J M
关节点是:
G B D A
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: