矩阵(稀疏矩阵)的转置算法(C语言实现)


所谓矩阵转置,就是将矩阵中每个元素的行标和列标互换,转置后的新矩阵称为转置矩阵。举个简单的例子:
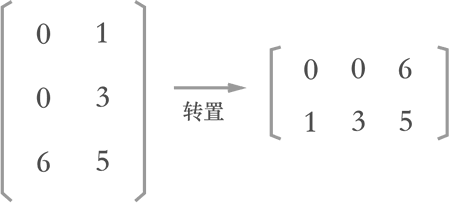
图 1 矩阵转置示意图
实现矩阵转置,C 语言经常使用二维数组,代码如下:
上面这种方法适用于各种矩阵,当然也包括稀疏矩阵。但是,采用此方式转置稀疏矩阵的效率不高,体现在以下两个方面:
为了避免以上两个问题,可以考虑用三元组顺序表来存储稀疏矩阵,如下图所示:
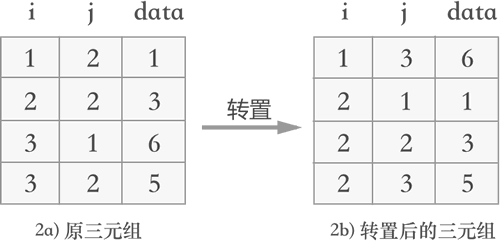
图 2 三元组表的变化
例如,对图 2a) 存储的稀疏矩阵进行转置,实现过程如下:
对比图 4b) 和图 2b) 可以看到,稀疏矩阵被成功地转置,且新表中各三元组的次序也是正确的。
稀疏矩阵转置的 C 语言实现代码为:
文章开头的转置算法中,嵌套的两个 for 循环的执行次数可以用 mu*nu(行数 * 列数)来表示;稀疏矩阵的转置算法中也嵌套使用了两个 for 循环,执行次数可以用 nu*tu(列数 * 非 0 元素个数)来表示。假设稀疏矩阵中非 0 元素的个数为 mu*nu,则稀疏矩阵转置算法中的嵌套 for 循环要执行 mu*nu2 次,执行效率没有文章开头的算法高。
也就是说,和文章开头的矩阵转置算法相比,稀疏矩阵的转置算法更节省内存空间,但执行效率不一定比前者高。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
图 1 矩阵转置示意图
实现矩阵转置,C 语言经常使用二维数组,代码如下:
#include<stdio.h>
#define ROW 3
#define COL 2
int main() {
//原矩阵
int num[ROW][COL] = { {0,1},{0,3},{6,5} };
//存储转置矩阵
int transNum[COL][ROW] = { 0 };
int i, j;
//矩阵转置
for (i = 0; i < ROW; i++) {
for (j = 0; j < COL; j++) {
transNum[j][i] = num[i][j];
}
}
//输出转置后的矩阵
for (i = 0; i < COL; i++) {
for (j = 0; j < ROW; j++) {
printf("%d ", transNum[i][j]);
}
putchar('\n');
}
return 0;
}
运行结果为:
0 0 6
1 3 5
上面这种方法适用于各种矩阵,当然也包括稀疏矩阵。但是,采用此方式转置稀疏矩阵的效率不高,体现在以下两个方面:
- 稀疏矩阵内部只有少量的非 0 元素,用二维数组存储稀疏矩阵,会存储很多个 0,造成内存空间的浪费;
- 稀疏矩阵在转置过程中,会有很多的 0 元素执行第 13 行代码存放到新矩阵中,而新矩阵中原本就都是 0 元素,所以这些赋值操作是没有意义的。
为了避免以上两个问题,可以考虑用三元组顺序表来存储稀疏矩阵,如下图所示:
图 2 三元组表的变化
图 2a) 表示的是图 1 中转置之前矩阵的三元组表,2b) 表示的是图 1 中矩阵转置后对应的三元组表。
注意,除了将每个三元组的行标和列标互换外,还要互换矩阵的行数和列数。稀疏矩阵的转置算法
也就是说,稀疏矩阵的转置需要完成以下 3 步:- 将稀疏矩阵的行数和列数互换;
- 将三元组表(存储矩阵)中的 i 列和 j 列互换,实现矩阵的转置;
- 以 j 列为序,重新排列三元组表中存储各三元组的先后顺序;
转置稀疏矩阵的实现思路是:从头遍历三元组顺序表,每次找到表中 j 列最小的三元组,互换行标和列标的值,然后存储到一个新三元组表中。有读者会问,前两步就可以实现稀疏矩阵的转置,为什么还要执行第 3 步呢?通常情况下,存储稀疏矩阵的三元组顺序表中,各个三元组会以行标做升序排序,行标相同的三元组以列标做升序排序。
例如,对图 2a) 存储的稀疏矩阵进行转置,实现过程如下:
- 新建一个三元组顺序表(用于存储转置矩阵),新表的行数为原表的列数,新表的列数为原表的行数;
-
遍历原顺序表,找到表中 j 列值最小的三元组 (3, 1, 6),将其行标和列标互换后添加到新表中,如图 3 所示:
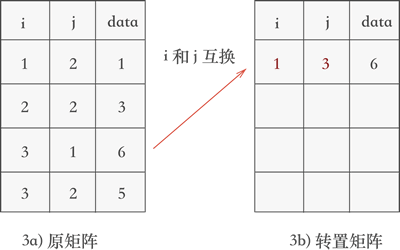
图 3 矩阵转置的第一个过程
-
再次遍历三元组表,找到表中 j 列值次小的三元组,依次为 (1, 2, 1)、(2, 2, 3) 和 (3, 2, 5),根据找到的先后次序将它们的行标和列标互换后添加到新表中,如图 4 所示:
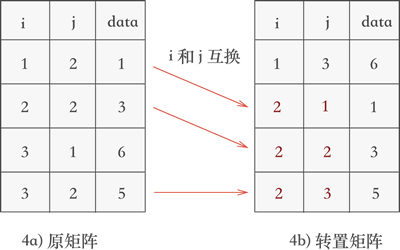
图 4 矩阵转置的第二个过程
对比图 4b) 和图 2b) 可以看到,稀疏矩阵被成功地转置,且新表中各三元组的次序也是正确的。
稀疏矩阵转置的 C 语言实现代码为:
#include<stdio.h>
#define NUM 10
//三元组
typedef struct {
int i, j;
int data;
}triple;
//三元组顺序表
typedef struct {
triple data[NUM];
int mu, nu, tu;
}TSMatrix;
//稀疏矩阵的转置
void transposeMatrix(TSMatrix M, TSMatrix* T) {
//1.稀疏矩阵的行数和列数互换
(*T).mu = M.nu;
(*T).nu = M.mu;
(*T).tu = M.tu;
if ((*T).tu) {
int col, p;
int q = 0;
//2.遍历原表中的各个三元组
for (col = 1; col <= M.nu; col++) {
//重复遍历原表 M.m 次,将所有三元组都存放到新表中
for (p = 0; p < M.tu; p++) {
//3.每次遍历,找到 j 列值最小的三元组,将它的行、列互换后存储到新表中
if (M.data[p].j == col) {
(*T).data[q].i = M.data[p].j;
(*T).data[q].j = M.data[p].i;
(*T).data[q].data = M.data[p].data;
//为存放下一个三元组做准备
q++;
}
}
}
}
}
int main() {
int i, k;
TSMatrix M, T;
M.mu = 3;
M.nu = 2;
M.tu = 4;
M.data[0].i = 1;
M.data[0].j = 2;
M.data[0].data = 1;
M.data[1].i = 2;
M.data[1].j = 2;
M.data[1].data = 3;
M.data[2].i = 3;
M.data[2].j = 1;
M.data[2].data = 6;
M.data[3].i = 3;
M.data[3].j = 2;
M.data[3].data = 5;
for (k = 0; k < NUM; k++) {
T.data[k].i = 0;
T.data[k].j = 0;
T.data[k].data = 0;
}
transposeMatrix(M, &T);
for (i = 0; i < T.tu; i++) {
printf("(%d,%d,%d)\n", T.data[i].i, T.data[i].j, T.data[i].data);
}
return 0;
}
程序运行结果为:
(1,3,6)
(2,1,1)
(2,2,3)
(2,3,5)
文章开头的转置算法中,嵌套的两个 for 循环的执行次数可以用 mu*nu(行数 * 列数)来表示;稀疏矩阵的转置算法中也嵌套使用了两个 for 循环,执行次数可以用 nu*tu(列数 * 非 0 元素个数)来表示。假设稀疏矩阵中非 0 元素的个数为 mu*nu,则稀疏矩阵转置算法中的嵌套 for 循环要执行 mu*nu2 次,执行效率没有文章开头的算法高。
也就是说,和文章开头的矩阵转置算法相比,稀疏矩阵的转置算法更节省内存空间,但执行效率不一定比前者高。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: