顺序查找算法(C语言实现)


使用线性存储结构表示静态查找表时,可以借助顺序查找算法在表中查找特定的元素。
当然,如果表中的所有元素都和目标元素对比了一遍,最终没有找到目标元素,表明查找表中没有目标元素,查找失败。
举个简单的例子,在 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44} 集合中,借助顺序查找算法查找 33 的过程是:
1) 假设从元素 10 开始向右逐个查找。显然,元素 10 不是要找的目标元素:

图 1 查看 10 是否为目标元素
2) 继续查看表中的下一个元素 14,也不是要找的目标元素:

图 2 查看 14 是否为目标元素
3) 采用同样的方法,逐个查看表中的各个元素是否为目标元素,整个查找过程如下图的动画所示:

图 3 顺序查找目标元素的过程
成功找到目标元素后,顺序查找随即结束。当表中不包含目标元素时,顺序查找算法会比对至最后一个元素,然后停止执行。
顺序查找算法的常规实现思路是:将表中元素逐一和目标元素进行比对,每次比对失败,判断一下整张表是否查找完毕,如果表中还有未比对的元素,就继续比对,反之算法执行结束。
以常规的思路实现顺序查找算法,每次查找都要进行两次判断,既要判断当前元素是否为目标元素,还要判断整张表是否查找完毕。这里给大家提供一种更高效的解决方案:在查找表中的一端添加目标元素,顺序查找算法从查找表的另一端执行。
仍以 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44} 集合为例,在表中查找元素 5。首先将元素 5 放置到表的尾部,顺序查找算法从表的头部开始查找元素 5,整个过程如下图所示:

图 4 顺序查找目标元素失败
这样做的好处是,查找过程中不必判断整张表是否查找完毕,因为无论查找能否成功,顺序查找算法都能正常执行结束。数据结构中,将在查找表一端添加的目标元素称为监视哨。
图 4 中,虽然顺序查找算法最终找到了目标元素,但此元素是我们额外添加到表中的,所以查找失败。
顺序查找算法的时间复杂度可以用
计算顺序查找算法的平均查找长度,可以借助《什么是查找表》一节给出的公式:
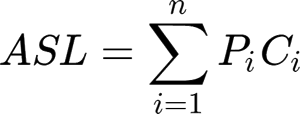
默认情况下,表中各个元素被查找到的概率是相同的,都是 1/n(n 为查找表中元素的数量),所以各个元素对应的 Pi 就是 1/n。
在给定的查找表中,顺序查找算法从表的一端开始查找,第一个元素对应的 C1=1,第二个元素对应的 C2=2,依次类推,所以表中第 i 个元素对应的 Ci 就是 i。
将 Pi=1/n 和 Ci=i 带入公式,求得的 ASL 为:
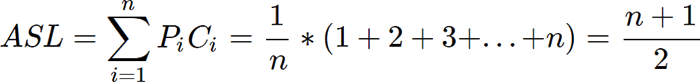
顺序查找算法对应的 ASL 值为 (n+1)/2,几乎为查找表长度的一半。这也就意味着,查找表中包含的元素越多,顺序查找算法的 ASL 值越大,查找性能越差,执行效率越低。
和其它查找算法相比,顺序查找算法的时间复杂度较大,同样平均查找长度也较大,查找表中的元素数量越多,算法的性能越差。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
顺序查找算法(Sequential Search)又称顺序搜索算法或者线性搜索算法,是所有查找算法中最基础、最简单的。顺序查找算法适用于绝大多数场景,查找表中存放有序序列或者无序序列,都可以使用此算法。所谓静态查找表,即只能对表内的元素做查找和读取操作,不允许插入或删除元素。
顺序查找算法的实现思路
顺序查找算法很容易理解,就是从查找表的一端开始,将表中的元素逐一和目标元素做比较,直至找到目标元素。当然,如果表中的所有元素都和目标元素对比了一遍,最终没有找到目标元素,表明查找表中没有目标元素,查找失败。
举个简单的例子,在 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44} 集合中,借助顺序查找算法查找 33 的过程是:
1) 假设从元素 10 开始向右逐个查找。显然,元素 10 不是要找的目标元素:
图 1 查看 10 是否为目标元素
2) 继续查看表中的下一个元素 14,也不是要找的目标元素:
图 2 查看 14 是否为目标元素
3) 采用同样的方法,逐个查看表中的各个元素是否为目标元素,整个查找过程如下图的动画所示:
图 3 顺序查找目标元素的过程
成功找到目标元素后,顺序查找随即结束。当表中不包含目标元素时,顺序查找算法会比对至最后一个元素,然后停止执行。
顺序查找算法的常规实现思路是:将表中元素逐一和目标元素进行比对,每次比对失败,判断一下整张表是否查找完毕,如果表中还有未比对的元素,就继续比对,反之算法执行结束。
以常规的思路实现顺序查找算法,每次查找都要进行两次判断,既要判断当前元素是否为目标元素,还要判断整张表是否查找完毕。这里给大家提供一种更高效的解决方案:在查找表中的一端添加目标元素,顺序查找算法从查找表的另一端执行。
仍以 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44} 集合为例,在表中查找元素 5。首先将元素 5 放置到表的尾部,顺序查找算法从表的头部开始查找元素 5,整个过程如下图所示:
图 4 顺序查找目标元素失败
这样做的好处是,查找过程中不必判断整张表是否查找完毕,因为无论查找能否成功,顺序查找算法都能正常执行结束。数据结构中,将在查找表一端添加的目标元素称为监视哨。
图 4 中,虽然顺序查找算法最终找到了目标元素,但此元素是我们额外添加到表中的,所以查找失败。
实践证明,当查找表中的元素个数多于 1000 个时,使用图 4 这种解决方案可以大大缩减查找过程所需的时间。
顺序查找算法的具体实现
线性存储结构具体可以分为两类,分别是顺序表和单链表。这里以顺序表为例,实现顺序查找算法的 C 语言程序如下:
#include <stdio.h>
#include <stdlib.h>
#define keyType int
typedef struct {
keyType key;//查找表中每个数据元素的值
//如果需要,还可以添加其他属性
}ElemType;
//顺序表表示查找表
typedef struct {
ElemType* elem; //存放查找表中数据元素的数组
int length; //记录查找表中数据的总数量
}SSTable;
//创建查找表
void Create(SSTable* st, int length) {
int i;
st->elem = (ElemType*)malloc((length + 1) * sizeof(ElemType)); // +1 是为了给监视哨留出位置
st->length = length;
printf("输入表中的数据元素:\n");
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
for (i = 0; i < length; i++) {
scanf("%d", &(st->elem[i].key));
}
}
//查找表查找的功能函数,其中key为关键字
int Search_seq(SSTable st, keyType key) {
int i;
st.elem[st.length].key = key;//将目标元素存放在顺序表最后的位置,起监视哨的作用
//从查找表第一个元素开始,直至找到目标元素
for (i = 0; st.elem[i].key != key; i++);
//如果 i=st.length,说明查找失败;反之,返回的是含有关键字key的数据元素在查找表中的位置
return i;
}
int main() {
int key, location, len;
SSTable st;
printf("输入查找表中的元素个数:");
scanf("%d", &len);
Create(&st, len);
printf("请输入查找数据的关键字:");
scanf("%d", &key);
location = Search_seq(st, key);
if (location == st.length) {
printf("查找失败");
}
else {
printf("目标元素在查找表中的位置为:%d", location + 1);
}
free(st.elem);
return 0;
}
以在 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44} 查找元素 33 为例,程序的执行结果为:
输入查找表中的元素个数:10
输入表中的数据元素:
10 14 19 26 27 31 33 35 42 44
请输入查找数据的关键字:33
目标元素在查找表中的位置为:7
用链式结构(单链表)表示静态查找表,顺序查找算法的实现过程和上面程序类似,这里不再给出具体的实现程序。
顺序查找算法的性能分析
衡量顺序查找算法的性能,可以计算它的时间复杂度,也可以计算它的平均查找长度(ASL)。顺序查找算法的时间复杂度可以用
O(n)表示(n 为查找表中的元素数量)。查找表中的元素越多,顺序查找算法的执行效率越低。计算顺序查找算法的平均查找长度,可以借助《什么是查找表》一节给出的公式:
默认情况下,表中各个元素被查找到的概率是相同的,都是 1/n(n 为查找表中元素的数量),所以各个元素对应的 Pi 就是 1/n。
在给定的查找表中,顺序查找算法从表的一端开始查找,第一个元素对应的 C1=1,第二个元素对应的 C2=2,依次类推,所以表中第 i 个元素对应的 Ci 就是 i。
将 Pi=1/n 和 Ci=i 带入公式,求得的 ASL 为:
顺序查找算法对应的 ASL 值为 (n+1)/2,几乎为查找表长度的一半。这也就意味着,查找表中包含的元素越多,顺序查找算法的 ASL 值越大,查找性能越差,执行效率越低。
总结
顺序查找算法的优点是实现简单、适用于绝大多数场景。和其它查找算法相比,顺序查找算法的时间复杂度较大,同样平均查找长度也较大,查找表中的元素数量越多,算法的性能越差。
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: