一文彻底搞懂栈和队列(超级肝,新手必看)


栈和队列存储的都是逻辑关系为“一对一”的数据,本质上它们也属于线性存储结构。
栈存储数据,讲究“先进后出”,即最先进栈的数据,最后出栈;队列存储数据,讲究"先进先出",即最先进队列的数据,也最先出队列。
根据数据在物理内存中的存储状态,栈分为顺序栈和链栈,队列分为顺序队列和链式队列。
1) 元素进栈和出栈的操作只能从一端完成,另一端是封闭的,如下图所示:

图 1 栈存储结构示意图
通常,我们将元素进栈的过程简称为“入栈”、“进栈”或者“压栈”;将元素出栈的过程简称为“出栈”或者“弹栈”。
2) 栈中无论存数据还是取数据,都必须遵循“先进后出”的原则,即最先入栈的元素最先出栈。以图 1 的栈为例,很容易可以看出是元素 1 最先入栈,然后依次是元素 2、3、4 入栈。在此基础上,如果想取出元素 1,根据“先进后出”的原则,必须先依次将元素 4、3、2 出栈,最后才能轮到元素 1 出栈。
我们习惯将栈的开口端称为栈顶,封口端称为栈底。例如在图 1 中,元素 4 一侧为栈顶,元素 1 一侧为栈底,如图 2 所示。
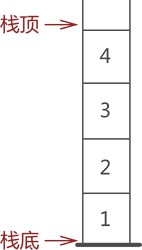
图 2 栈顶和栈底
由此我们可以对栈存储结构下一个定义:栈一种“只能从一端存取元素,且存取过程必须遵循‘先进后出’原则”的线性存储结构。
① 实现浏览器的“回退”功能
所谓浏览器的“回退”功能,比如您用浏览器打开 A 页面,然后从 A 页面跳转到 B 页面,然后再从 B 页面跳转到 C 页面。这种情况下,如果想回到 A 页面,有两种方法:
② 实现 C 语言函数的相互调用
C语言程序中,函数间的相互调用过程也是用栈存储结构实现的。
举个简单的例子:
程序执行时,main() 函数会最先入栈,执行到第 5 行代码时,需要执行 func() 函数,此时会将 func() 函数入栈。等待 func() 函数执行完后,func() 函数会出栈,此时 main() 函数中的剩余代码会继续执行,直至 main() 函数执行完毕,做出栈操作,整个程序就执行结束了。
③ 解决一些实际问题
借助栈存储结构,可以快速解决类似“进制转换”、“括号匹配”等问题,具体的解决过程会在后续文章中做详细讲解。
显然,顺序栈和链栈两种实现方案,本质的区别仍然是顺序表和链表之间的区别,即顺序栈是将所有数据集中存储,而链栈是将数据分散存放,元素之间的逻辑关系靠指针维系。
顺序表和栈存储数据的方式高度相似,只不过栈对数据的存取过程有特殊的限制,而顺序表没有。例如,我们使用顺序表(用 a 数组表示)存储

图 3 顺序表存储 {1,2,3,4}
使用栈存储结构存储

图 4 栈结构存储 {1,2,3,4}
对比图3 和图 4 不难看出,用顺序表模拟栈结构很简单,只要将数据从数组下标为 0 的位置依次存储即可。
栈中存取元素,必须遵循“先进后出”的原则,因此若想将图 3 中存储的元素 1 从栈中取出,需依次先将元素 4、元素 3 和元素 2 从栈中取出,最后才能取出元素 1。
这里给出一种顺序表模拟入栈和出栈的实现思路:定义一个实时记录栈顶位置的变量(假设命名为 top),初始状态下栈内无任何元素,整个栈是"空栈",top 的值为 -1。一旦有数据元素进栈,则 top 就做 +1 操作;反之,如果数据元素出栈,top 就做 -1 操作。
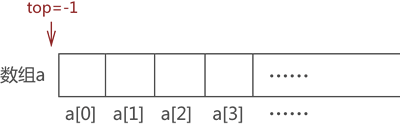
图 5 空栈示意图
将元素 1 入栈,默认数组下标为 0 一端表示栈底,元素 1 存储在数组 a[0] 处,同时 top 值 +1,如图 6 所示:
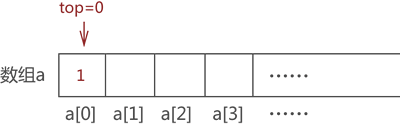
图 6 模拟栈存储元素 1
采用同样的方式,依次将元素 2、3 和 4 入栈,最终 top 的值变成 3,如图 7 所示:
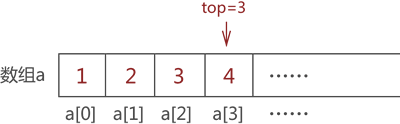
图 7 模拟栈存储{1,2,3,4}
因此,C 语言实现代码为:
比如,将图 7 中的元素 2 出栈,则需要先将元素 4 和元素 3 依次出栈。需要注意的是,当有数据出栈时,要将 top 做 -1 操作。因此,元素 4 和元素 3 出栈的过程分别如图 8a) 和 8b) 所示:
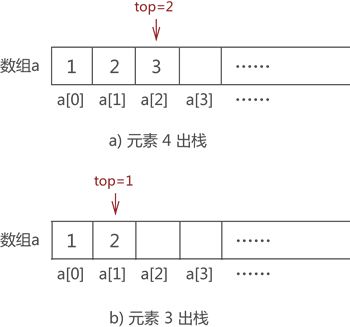
图 8 数据元素出栈
元素 4 和元素 3 全部出栈后,元素 2 才能出栈。因此,使用顺序表模拟数据出栈操作的 C 语言实现代码为:
链栈的实现思路和顺序栈类似,顺序栈是将顺序表(数组)的一端做栈底,另一端做栈顶;链栈也是如此,我们通常将链表的头部做栈顶,尾部做栈底,如图 9 所示:

图 9 链栈示意图
以链表的头部做栈顶,最大的好处是:可以避免在实现元素 "入栈" 和 "出栈" 时做大量遍历链表的耗时操作。有元素入栈时,只需要将其插入到链表的头部;有元素出栈时,只需要从链表的头部依次摘取结点。
因此,链栈实际上是一个采用头插法插入或删除数据的链表。

图 10 链栈元素依次入栈过程示意图
C语言实现代码为:
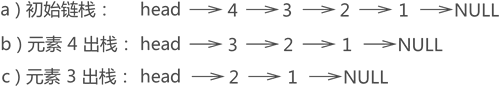
图 11 链栈元素出栈示意图
实现栈顶元素出栈的 C 语言代码为:
这里给大家列举了 4 个题目,大家可以先尝试独立实现:
和顺序表、链表相比,队列的特殊性体现在以下两个方面:
1、元素只能从队列的一端进入,从另一端出去,如下图所示:
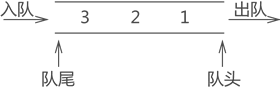
图 12 队列存储结构
通常,我们将元素进入队列的一端称为“队尾”,进入队列的过程称为“入队”;将元素从队列中出去的一端称为“队头”,出队列的过程称为“出队”。
2、队列中各个元素的进出必须遵循“先进先出”的原则,即最先入队的元素必须最先出队。
以图 12 所示的队列为例,从各个元素在队列中的存储状态不难判定,元素 1 最先入队,然后是元素 2 入队,最后是元素 3 入队。如果此时想将元素 3 出队,根据“先进先出”原则,必须先将元素 1 和 2 依次出队,最后才能轮到元素 3 出队。
对于一台计算机来说,CPU 通常只有 1 个,是非常重要的资源。如果在很短的时间内,有多个程序向操作系统申请使用 CPU,就会出现竞争 CPU 资源的现象。不同的操作系统,解决这一问题的方法是不一样的,有一种方法就用到了队列这种存储结构。
假设在某段时间里,有 A、B、C 三个程序向操作系统申请 CPU 资源,操作系统会根据它们的申请次序,将它们排成一个队列。根据“先进先出”原则,最先进队列的程序出队列,并获得 CPU 的使用权。待该程序执行完或者使用 CPU 一段时间后,操作系统会将 CPU 资源分配给下一个出队的程序,以此类推。如果该程序在获得 CPU 资源的时间段内没有执行完,则只能重新入队,等待操作系统再次将 CPU 资源分配给它。
队列还可以用来解决一些实际问题,比如实现一个简单的停车场管理系统、实现一个推小车卡牌游戏等,后续会做详细讲解。
两者的区别仅是顺序表和链表的区别,即顺序队列集中存储数据,而链队列分散存储数据,元素之间的逻辑关系靠指针维系。
我们知道,队列具有以下两个特点:
在顺序表的基础上,只要元素进出的过程遵循以上两个规则,就能实现队列结构。
通常情况下,我们采用 C 语言中的数组实现顺序表。既然用顺序表模拟实现队列,必然要先定义一个足够大的数组。不仅如此,为了遵守队列中数据从 "队尾进,队头出" 且 "先进先出" 的规则,还需要定义两个变量(top 和 rear)分别记录队头和队尾的具体位置,如下图所示:
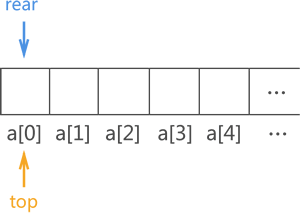
图 13 顺序队列实现示意图
初始状态下,顺序队列中没有任何元素,因此 top 和 rear 重合,都位于 a[0] 处。
例如,在图 13 基础上将
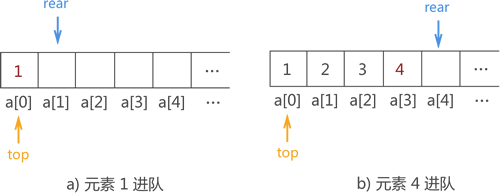
图 14 数据进顺序队列的过程实现示意图
入队操作的 C 语言实现代码如下:
出队操作的实现方法很简单,就是更新 top 的值(top+1)。例如,在图 14 基础上,顺序队列中元素逐个队列的过程如图 15 所示:
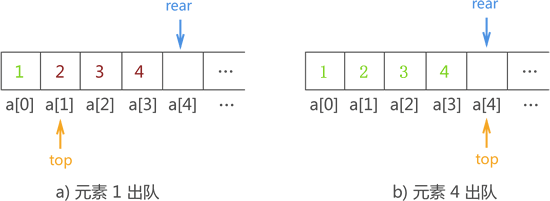
图 15 数据出顺序队列的过程示意图
也就是说,在元素不断入队、出队的过程中,顺序队列会整体向顺序表的尾部移动。整个实现方案存在的缺陷是:
在《循环队列完全攻略》一节中,我会教大家顺序队列的另一种实现方案,可以彻底弥补以上两个缺陷。
链式队列的实现思想同顺序队列类似,创建两个指针(命名为 top 和 rear)分别指向链表中队列的队头元素和队尾元素,如下图所示:
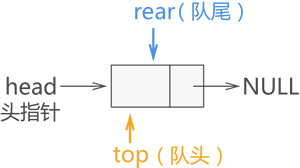
图 16 链式队列的初始状态
图 16 所示为链式队列的初始状态,此时队列中没有存储任何数据元素,因此 top 和 rear 指针都同时指向头节点。
由此,新节点就入队成功了。
例如,在图 16 的基础上,我们依次将
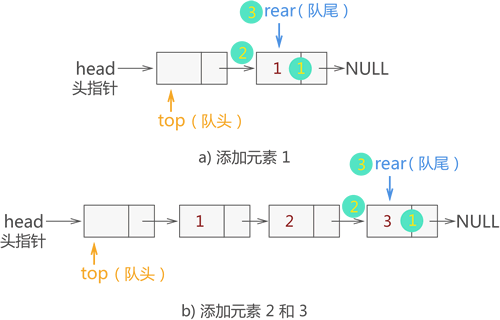
图 17 {1,2,3} 入链式队列
我们知道,队列中的元素只能从队头出队。在图 17 中,队列的队头位于链表的头部。因此队列中元素出队的过程,其实是链表中摘除首元结点的过程,需要做以下 3 步操作:
例如,在图 17b) 的基础上,我们将元素 1 和 2 出队,则操作过程如图 18 所示:
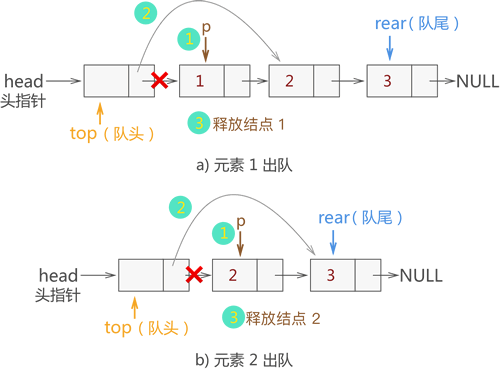
图 18 链式队列中数据元素出队
链式队列中队头元素出队的 C 语言实现代码为:
前面在学习顺序队列时,由于顺序表的局限性,我们在顺序队列中实现数据入队和出队的基础上,又对实现代码做了改进,令其能够充分利用数组中的空间。链式队列就不需要考虑空间利用的问题,因为链式队列本身就是实时申请空间。因此,这可以算作是链式队列相比顺序队列的一个优势。
这里给出链式队列入队和出队的完整 C 语言代码为:
这里给大家列举了 4 个题目,大家可以先尝试独立实现:
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
栈存储数据,讲究“先进后出”,即最先进栈的数据,最后出栈;队列存储数据,讲究"先进先出",即最先进队列的数据,也最先出队列。
根据数据在物理内存中的存储状态,栈分为顺序栈和链栈,队列分为顺序队列和链式队列。
数据结构中的栈
1、栈是什么
栈是一种“特殊”的线性存储结构,它的特殊之处体现在以下两个地方:1) 元素进栈和出栈的操作只能从一端完成,另一端是封闭的,如下图所示:
图 1 栈存储结构示意图
通常,我们将元素进栈的过程简称为“入栈”、“进栈”或者“压栈”;将元素出栈的过程简称为“出栈”或者“弹栈”。
2) 栈中无论存数据还是取数据,都必须遵循“先进后出”的原则,即最先入栈的元素最先出栈。以图 1 的栈为例,很容易可以看出是元素 1 最先入栈,然后依次是元素 2、3、4 入栈。在此基础上,如果想取出元素 1,根据“先进后出”的原则,必须先依次将元素 4、3、2 出栈,最后才能轮到元素 1 出栈。
我们习惯将栈的开口端称为栈顶,封口端称为栈底。例如在图 1 中,元素 4 一侧为栈顶,元素 1 一侧为栈底,如图 2 所示。
图 2 栈顶和栈底
由此我们可以对栈存储结构下一个定义:栈一种“只能从一端存取元素,且存取过程必须遵循‘先进后出’原则”的线性存储结构。
栈的实际应用
对于刚刚接触栈存储结构的读者来说,可能很难理解为什么会设计出“栈”这种存储结构,它有什么用?栈是一种特殊的线性存储结构,借助它的“特殊性”,可以解决很多实际问题。① 实现浏览器的“回退”功能
所谓浏览器的“回退”功能,比如您用浏览器打开 A 页面,然后从 A 页面跳转到 B 页面,然后再从 B 页面跳转到 C 页面。这种情况下,如果想回到 A 页面,有两种方法:
- 重新搜索找到 A 页面;
- 借助浏览器的“回退”功能,先从 C 页面回退到 B 页面,再从 B 页面回退到 A 页面。
浏览器的“回退”功能底层就是用栈存储结构实现的,当从 A 页面跳转到 B 页面时,浏览器会执行入栈操作,A 页面信息会存入栈中;同样,从 B 页面跳转到 C 页面时,B 页面信息会存入栈中。当点击浏览器的“回退”按钮时,浏览器会执行“出栈”操作,根据“先进后出”的原则,B 页面先出栈,然后 A 页面出栈,这样就实现了“回退”的功能。很多浏览器的“回退”功能就位于工具栏中,图标是一个类似
←的箭头。
② 实现 C 语言函数的相互调用
C语言程序中,函数间的相互调用过程也是用栈存储结构实现的。
举个简单的例子:
void func(){
printf("Hello,World!");
}
int main(){
func();
return 0;
}
这段 C 语言程序中有两个函数,分别是 main() 函数和 func() 函数,其中 main() 函数内部调用了 func() 函数。程序执行时,main() 函数会最先入栈,执行到第 5 行代码时,需要执行 func() 函数,此时会将 func() 函数入栈。等待 func() 函数执行完后,func() 函数会出栈,此时 main() 函数中的剩余代码会继续执行,直至 main() 函数执行完毕,做出栈操作,整个程序就执行结束了。
③ 解决一些实际问题
借助栈存储结构,可以快速解决类似“进制转换”、“括号匹配”等问题,具体的解决过程会在后续文章中做详细讲解。
栈的具体实现
和线性表类似,栈存储结构也有两种具体的实现方案:显然,顺序栈和链栈两种实现方案,本质的区别仍然是顺序表和链表之间的区别,即顺序栈是将所有数据集中存储,而链栈是将数据分散存放,元素之间的逻辑关系靠指针维系。
2、顺序栈的基本操作(入栈和出栈)
顺序栈指的是用顺序表实现的栈存储结构,接下来讲解如何用顺序表模拟栈结构,以及实现元素的入栈和出栈操作。顺序表和栈存储数据的方式高度相似,只不过栈对数据的存取过程有特殊的限制,而顺序表没有。例如,我们使用顺序表(用 a 数组表示)存储
{1,2,3,4},存储状态如图 3 所示:图 3 顺序表存储 {1,2,3,4}
使用栈存储结构存储
{1,2,3,4},存储状态如图 4 所示:图 4 栈结构存储 {1,2,3,4}
对比图3 和图 4 不难看出,用顺序表模拟栈结构很简单,只要将数据从数组下标为 0 的位置依次存储即可。
从数组下标为 0 的模拟栈存储数据是常用的方法,从其他数组下标处存储数据也完全可以,这里只是为了方便初学者理解。
了解了顺序表模拟实现栈存储结构之后,接下来学习如何实现元素入栈和出栈的操作。栈中存取元素,必须遵循“先进后出”的原则,因此若想将图 3 中存储的元素 1 从栈中取出,需依次先将元素 4、元素 3 和元素 2 从栈中取出,最后才能取出元素 1。
这里给出一种顺序表模拟入栈和出栈的实现思路:定义一个实时记录栈顶位置的变量(假设命名为 top),初始状态下栈内无任何元素,整个栈是"空栈",top 的值为 -1。一旦有数据元素进栈,则 top 就做 +1 操作;反之,如果数据元素出栈,top 就做 -1 操作。
顺序栈元素"入栈"
比如,还是模拟栈存储{1,2,3,4} 的过程。最初栈是"空栈",top 的值为 -1,如图 5 所示:
图 5 空栈示意图
将元素 1 入栈,默认数组下标为 0 一端表示栈底,元素 1 存储在数组 a[0] 处,同时 top 值 +1,如图 6 所示:
图 6 模拟栈存储元素 1
采用同样的方式,依次将元素 2、3 和 4 入栈,最终 top 的值变成 3,如图 7 所示:
图 7 模拟栈存储{1,2,3,4}
因此,C 语言实现代码为:
//元素elem进栈,a为数组,top值为当前栈的栈顶位置
int push(int* a,int top,int elem){
a[++top]=elem;
return top;
}
代码中的 a[++top]=elem,等价于先执行 ++top,再执行 a[top]=elem。顺序栈元素"出栈"
实际上,top 变量的设置对模拟数据的 "入栈" 操作没有帮助,它是为实现数据的 "出栈" 操作做准备的。比如,将图 7 中的元素 2 出栈,则需要先将元素 4 和元素 3 依次出栈。需要注意的是,当有数据出栈时,要将 top 做 -1 操作。因此,元素 4 和元素 3 出栈的过程分别如图 8a) 和 8b) 所示:
图 8 数据元素出栈
元素 4 和元素 3 全部出栈后,元素 2 才能出栈。因此,使用顺序表模拟数据出栈操作的 C 语言实现代码为:
//数据元素出栈
int pop(int * a,int top){
if (top == -1) {
printf("空栈");
return -1;
}
printf("弹栈元素:%d\n",a[top]);
top--;
return top;
}
代码中的 if 语句是为了防止用户做 "栈中已无数据却还要做出栈操作" 的错误操作。细心的读者还可能发现,出栈操作只是将 top 的值减 1,并没有像图 6 那样将出栈元素从数组中手动删除。这是因为,当有新的元素入栈后,新元素会将出栈元素覆盖掉,所以不删除出栈元素,也不会影响栈的正常使用,何必多此一举。总结
通过学习顺序表模拟栈中数据入栈和出栈的操作,初学者完成了对顺序栈的学习,这里给出顺序栈及对数据基本操作的 C 语言完整代码:
#include <stdio.h>
//元素elem进栈
int push(int* a, int top, int elem) {
a[++top] = elem;
return top;
}
//数据元素出栈
int pop(int* a, int top) {
if (top == -1) {
printf("空栈");
return -1;
}
printf("弹栈元素:%d\n", a[top]);
top--;
return top;
}
int main() {
int a[100];
int top = -1;
top = push(a, top, 1);
top = push(a, top, 2);
top = push(a, top, 3);
top = push(a, top, 4);
top = pop(a, top);
top = pop(a, top);
top = pop(a, top);
top = pop(a, top);
top = pop(a, top);
return 0;
}
程序输出结果为:
弹栈元素:4
弹栈元素:3
弹栈元素:2
弹栈元素:1
空栈
3、链栈的基本操作(入栈和出栈)
链栈是栈的一种实现方法,特指用链表实现栈存储结构。链栈的实现思路和顺序栈类似,顺序栈是将顺序表(数组)的一端做栈底,另一端做栈顶;链栈也是如此,我们通常将链表的头部做栈顶,尾部做栈底,如图 9 所示:
图 9 链栈示意图
以链表的头部做栈顶,最大的好处是:可以避免在实现元素 "入栈" 和 "出栈" 时做大量遍历链表的耗时操作。有元素入栈时,只需要将其插入到链表的头部;有元素出栈时,只需要从链表的头部依次摘取结点。
因此,链栈实际上是一个采用头插法插入或删除数据的链表。
链栈元素入栈
例如,依次将 1、2、3、4 存储到栈中,每个元素的入栈过程如图 10 所示:图 10 链栈元素依次入栈过程示意图
C语言实现代码为:
//链表中的节点结构
typedef struct lineStack {
int data;
struct lineStack* next;
}LineStack;
//stack为当前的链栈,a表示入栈元素
LineStack* push(LineStack* stack, int a) {
//创建存储新元素的节点
LineStack* line = (LineStack*)malloc(sizeof(LineStack));
line->data = a;
//新节点与头节点建立逻辑关系
line->next = stack;
//更新头指针的指向
stack = line;
return stack;
}
链栈元素出栈
在图 10e) 所示链表的基础上,假设将元素 3 从栈中取出,根据"先进后出"的原则,要先将元素 4 出栈,然后元素 3 才能出栈,整个操作过程如图 11 所示:图 11 链栈元素出栈示意图
实现栈顶元素出栈的 C 语言代码为:
//栈顶元素出链栈的实现函数
LineStack* pop(LineStack* stack) {
if (stack) {
//声明一个新指针指向栈顶节点
LineStack* p = stack;
//更新头指针
stack = stack->next;
printf("出栈元素:%d ", p->data);
if (stack) {
printf("新栈顶元素:%d\n", stack->data);
}
else {
printf("栈已空\n");
}
free(p);
}
else {
printf("栈内没有元素");
return stack;
}
return stack;
}
代码中通过使用 if 判断语句,避免了用户执行"栈已空却还要数据出栈"错误操作。总结
本节,通过采用头插法操作数据的单链表实现了链栈结构,这里给出链栈及基本操作的 C语言完整代码:
#include <stdio.h>
#include <stdlib.h>
//链表中的节点结构
typedef struct lineStack {
int data;
struct lineStack* next;
}LineStack;
//stack为当前的链栈,a表示入栈元素
LineStack* push(LineStack* stack, int a) {
//创建存储新元素的节点
LineStack* line = (LineStack*)malloc(sizeof(LineStack));
line->data = a;
//新节点与头节点建立逻辑关系
line->next = stack;
//更新头指针的指向
stack = line;
return stack;
}
//栈顶元素出链栈的实现函数
LineStack* pop(LineStack* stack) {
if (stack) {
//声明一个新指针指向栈顶节点
LineStack* p = stack;
//更新头指针
stack = stack->next;
printf("出栈元素:%d ", p->data);
if (stack) {
printf("新栈顶元素:%d\n", stack->data);
}
else {
printf("栈已空\n");
}
free(p);
}
else {
printf("栈内没有元素");
return stack;
}
return stack;
}
int main() {
LineStack* stack = NULL;
stack = push(stack, 1);
stack = push(stack, 2);
stack = push(stack, 3);
stack = push(stack, 4);
stack = pop(stack);
stack = pop(stack);
stack = pop(stack);
stack = pop(stack);
stack = pop(stack);
return 0;
}
程序运行结果为:
弹栈元素:4 栈顶元素:3
弹栈元素:3 栈顶元素:2
弹栈元素:2 栈顶元素:1
弹栈元素:1 栈已空
栈内没有元素
4、栈的实操
学到这里,读者已经掌握了栈的基本操作(入栈和出栈),接下来可以完成一些和栈相关的题目,用栈解决一些实际问题。这里给大家列举了 4 个题目,大家可以先尝试独立实现:
数据结构中的队列
1、队列是什么
队列用来存储逻辑关系为“一对一”的数据,是一种“特殊”的线性存储结构。和顺序表、链表相比,队列的特殊性体现在以下两个方面:
1、元素只能从队列的一端进入,从另一端出去,如下图所示:
图 12 队列存储结构
通常,我们将元素进入队列的一端称为“队尾”,进入队列的过程称为“入队”;将元素从队列中出去的一端称为“队头”,出队列的过程称为“出队”。
2、队列中各个元素的进出必须遵循“先进先出”的原则,即最先入队的元素必须最先出队。
以图 12 所示的队列为例,从各个元素在队列中的存储状态不难判定,元素 1 最先入队,然后是元素 2 入队,最后是元素 3 入队。如果此时想将元素 3 出队,根据“先进先出”原则,必须先将元素 1 和 2 依次出队,最后才能轮到元素 3 出队。
强调:栈和队列不要混淆,栈是一端开口、另一端封口,元素入栈和出栈遵循“先进后出”原则;队列是两端都开口,但元素只能从一端进,从另一端出,且进出队列遵循“先进先出”的原则。
队列的实际应用
队列在操作系统中应用的十分广泛,比如用它解决 CPU 资源的竞争问题。对于一台计算机来说,CPU 通常只有 1 个,是非常重要的资源。如果在很短的时间内,有多个程序向操作系统申请使用 CPU,就会出现竞争 CPU 资源的现象。不同的操作系统,解决这一问题的方法是不一样的,有一种方法就用到了队列这种存储结构。
假设在某段时间里,有 A、B、C 三个程序向操作系统申请 CPU 资源,操作系统会根据它们的申请次序,将它们排成一个队列。根据“先进先出”原则,最先进队列的程序出队列,并获得 CPU 的使用权。待该程序执行完或者使用 CPU 一段时间后,操作系统会将 CPU 资源分配给下一个出队的程序,以此类推。如果该程序在获得 CPU 资源的时间段内没有执行完,则只能重新入队,等待操作系统再次将 CPU 资源分配给它。
队列还可以用来解决一些实际问题,比如实现一个简单的停车场管理系统、实现一个推小车卡牌游戏等,后续会做详细讲解。
队列的具体实现
和栈的实现方案一样,队列的实现也有两种方式,分别是:两者的区别仅是顺序表和链表的区别,即顺序队列集中存储数据,而链队列分散存储数据,元素之间的逻辑关系靠指针维系。
2、顺序队列的基本操作(入队和出队)
顺序队列指的是用顺序表模拟实现的队列存储结构。我们知道,队列具有以下两个特点:
- 数据从队列的一端进,从另一端出;
- 数据的入队和出队遵循"先进先出"的原则;
在顺序表的基础上,只要元素进出的过程遵循以上两个规则,就能实现队列结构。
通常情况下,我们采用 C 语言中的数组实现顺序表。既然用顺序表模拟实现队列,必然要先定义一个足够大的数组。不仅如此,为了遵守队列中数据从 "队尾进,队头出" 且 "先进先出" 的规则,还需要定义两个变量(top 和 rear)分别记录队头和队尾的具体位置,如下图所示:
图 13 顺序队列实现示意图
初始状态下,顺序队列中没有任何元素,因此 top 和 rear 重合,都位于 a[0] 处。
实现入队
在图 13 的基础上,当有新元素入队时,依次执行以下两步操作:- 将新元素存储在 rear 记录的位置;
- 更新 rear 的值(rear+1),记录下一个空闲空间的位置,为下一个新元素入队做好准备。
例如,在图 13 基础上将
{1,2,3,4} 用顺序队列存储的实现操作如下图所示:
图 14 数据进顺序队列的过程实现示意图
入队操作的 C 语言实现代码如下:
int enQueue(int* a, int rear, int data) {
//如果 rear 超出数组下标范围,队列将无法继续添加元素
if (rear == MAX_LEN) {
printf("队列已满,添加元素失败\n");
return rear;
}
a[rear] = data;
rear++;
return rear;
}
实现出队
当有元素出队时,根据“先进先出”的原则,目标元素以及在它之前入队的元素要依次从队头出队。出队操作的实现方法很简单,就是更新 top 的值(top+1)。例如,在图 14 基础上,顺序队列中元素逐个队列的过程如图 15 所示:
图 15 数据出顺序队列的过程示意图
出队操作的 C 语言实现代码为:注意,虽然数组中仍保存着 1、2、3、4 这些元素,但队列中的元素是依靠 top 和 rear 来判别的,因此图 15b) 显示的队列中确实不存在任何元素。
int deQueue(int* a, int top, int rear) {
//如果 top==rear,表示队列为空
if (top== rear) {
printf("队列已空,出队执行失败\n");
return top;
}
printf("出队元素:%d\n", a[top]);
top++;
return top;
}
完整实现代码
使用顺序表模拟实现顺序队列的 C 语言代码为:
#include <stdio.h>
#define MAX_LEN 100 //规定数组的长度
//实现入队操作
int enQueue(int* a, int rear, int data) {
//如果 rear 超出数组下标范围,队列将无法继续添加元素
if (rear == MAX_LEN) {
printf("队列已满,添加元素失败\n");
return rear;
}
a[rear] = data;
rear++;
return rear;
}
//实现出队操作
int deQueue(int* a, int top, int rear) {
//如果 top==rear,表示队列为空
if (top == rear) {
printf("队列已空,出队执行失败\n");
return top;
}
printf("出队元素:%d\n", a[top]);
top++;
return top;
}
int main() {
int a[MAX_LEN];
int top, rear;
//设置队头指针和队尾指针,当队列中没有元素时,队头和队尾指向同一块地址
top = rear = 0;
//入队
rear = enQueue(a, rear, 1);
rear = enQueue(a, rear, 2);
rear = enQueue(a, rear, 3);
rear = enQueue(a, rear, 4);
//出队
top = deQueue(a, top, rear);
top = deQueue(a, top, rear);
top = deQueue(a, top, rear);
top = deQueue(a, top, rear);
top = deQueue(a, top, rear);
return 0;
}
程序输出结果:
出队元素:1
出队元素:2
出队元素:3
出队元素:4
队列已空,出队执行失败
顺序队列的缺陷
图 14b) 是所有数据入队成功的示意图,图 15b) 是所有数据出队后的示意图,对比两张图会发现,top 和 rear 重合位置变成了 a[4] 而不再是 a[0]。也就是说,在元素不断入队、出队的过程中,顺序队列会整体向顺序表的尾部移动。整个实现方案存在的缺陷是:
- 顺序队列前面的空闲空间无法再被使用,会造成空间浪费;
- 当顺序队列移动至顺序表尾部时,即便顺序表中有空闲空间,新元素也无法成功入队,我们习惯将这种现象称为“假溢出”。
在《循环队列完全攻略》一节中,我会教大家顺序队列的另一种实现方案,可以彻底弥补以上两个缺陷。
3、链式队列的基本操作(入队和出队)
链式队列,简称"链队列",即使用链表实现的队列存储结构。链式队列的实现思想同顺序队列类似,创建两个指针(命名为 top 和 rear)分别指向链表中队列的队头元素和队尾元素,如下图所示:
图 16 链式队列的初始状态
图 16 所示为链式队列的初始状态,此时队列中没有存储任何数据元素,因此 top 和 rear 指针都同时指向头节点。
在创建链式队列时,强烈建议初学者创建一个带有头节点的链表,这样实现链式队列会更简单。
由此,我们可以编写出创建链式队列的 C 语言实现代码为:
//链表中的节点结构
typedef struct qnode{
int data;
struct qnode * next;
}QNode;
//创建链式队列的函数
QNode * initQueue(){
//创建一个头节点
QNode * queue=(QNode*)malloc(sizeof(QNode));
//对头节点进行初始化
queue->next=NULL;
return queue;
}
链式队列数据入队
链队队列中,当有新的数据元素入队,只需进行以下 3 步操作:- 将该数据元素用节点包裹,例如新节点名称为 elem;
- 与 rear 指针指向的节点建立逻辑关系,即执行 rear->next=elem;
- 最后移动 rear 指针指向该新节点,即 rear=elem;
由此,新节点就入队成功了。
例如,在图 16 的基础上,我们依次将
{1,2,3} 依次入队,各个数据元素入队的过程如图 17 所示:
图 17 {1,2,3} 入链式队列
数据元素入链式队列的 C 语言实现代码为:如图 17 中,我们将链表的头部作为队列的队头,将链表的尾部作为队列的队尾。当然,也可以反过来,将链表的头部(尾部)作为队列的队尾(队头),两种存储方式都可以。
QNode* enQueue(QNode * rear,int data){
//1、用节点包裹入队元素
QNode * enElem=(QNode*)malloc(sizeof(QNode));
enElem->data=data;
enElem->next=NULL;
//2、新节点与rear节点建立逻辑关系
rear->next=enElem;
//3、rear指向新节点
rear=enElem;
//返回新的rear,为后续新元素入队做准备
return rear;
}
链式队列数据出队
当链式队列中有元素需要出队时,按照 "先进先出" 的原则,需要先将在它之前入队的元素依次出队,然后该目标元素才能出队。我们知道,队列中的元素只能从队头出队。在图 17 中,队列的队头位于链表的头部。因此队列中元素出队的过程,其实是链表中摘除首元结点的过程,需要做以下 3 步操作:
- 通过 top 指针直接找到队头节点,创建一个新指针 p 指向此即将出队的节点;
- 将 top 所指结点的 next 指针,指向 p 结点的直接后继结点;
- 释放节点 p 占用的内存空间;
例如,在图 17b) 的基础上,我们将元素 1 和 2 出队,则操作过程如图 18 所示:
图 18 链式队列中数据元素出队
链式队列中队头元素出队的 C 语言实现代码为:
QNode* DeQueue(QNode* top, QNode* rear) {
QNode* p = NULL;
if (top->next == NULL) {
printf("\n队列为空\n");
return rear;
}
// 1、创建新指针 p 指向目标结点
p = top->next;
printf("%d ", p->data);
//2、将目标结点从链表上摘除
top->next = p->next;
if (rear == p) {
rear = top;
}
//3、释放结点 p 占用的内存
free(p);
return rear;
}
注意,将队头元素做出队操作时,需提前判断队列中是否还有元素,如果没有,要提示用户无法做出队操作,保证程序的健壮性。此外,程序中要判断被摘除的目标结点是否是 rear 队头队尾,如果是的话,要及时更新 rear 指针的指向。总结
通过学习链式队列最基本的数据入队和出队操作,我们可以就实际问题,对以上代码做适当的修改。前面在学习顺序队列时,由于顺序表的局限性,我们在顺序队列中实现数据入队和出队的基础上,又对实现代码做了改进,令其能够充分利用数组中的空间。链式队列就不需要考虑空间利用的问题,因为链式队列本身就是实时申请空间。因此,这可以算作是链式队列相比顺序队列的一个优势。
这里给出链式队列入队和出队的完整 C 语言代码为:
#include <stdio.h>
#include <stdlib.h>
//链表中的节点结构
typedef struct qnode {
int data;
struct qnode* next;
}QNode;
//创建链式队列的函数
QNode* initQueue() {
//创建一个头节点
QNode* queue = (QNode*)malloc(sizeof(QNode));
//对头节点进行初始化
queue->next = NULL;
return queue;
}
QNode* enQueue(QNode* rear, int data) {
//1、用节点包裹入队元素
QNode* enElem = (QNode*)malloc(sizeof(QNode));
enElem->data = data;
enElem->next = NULL;
//2、新节点与rear节点建立逻辑关系
rear->next = enElem;
//3、rear指向新节点
rear = enElem;
//返回新的rear,为后续新元素入队做准备
return rear;
}
QNode* deQueue(QNode* top, QNode* rear) {
QNode* p = NULL;
if (top->next == NULL) {
printf("\n队列为空\n");
return rear;
}
// 1、创建新指针 p 指向目标结点
p = top->next;
printf("%d ", p->data);
//2、将目标结点从链表上摘除
top->next = p->next;
if (rear == p) {
rear = top;
}
//3、释放结点 p 占用的内存
free(p);
return rear;
}
int main() {
QNode* queue = NULL, * top = NULL, * rear = NULL;
queue = top = rear = initQueue();//创建头结点
//向链队列中添加结点,使用尾插法添加的同时,队尾指针需要指向链表的最后一个元素
rear = enQueue(rear, 1);
rear = enQueue(rear, 2);
rear = enQueue(rear, 3);
rear = enQueue(rear, 4);
//入队完成,所有数据元素开始出队列
rear = deQueue(top, rear);
rear = deQueue(top, rear);
rear = deQueue(top, rear);
rear = deQueue(top, rear);
rear = deQueue(top, rear);
return 0;
}
程序运行结果为:
1 2 3 4
队列为空
4、队列的实操
学到这里,读者已经掌握了队列的基本操作(出队和入队),接下来可以完成一些和队列相关的题目,用队列解决一些实际问题。这里给大家列举了 4 个题目,大家可以先尝试独立实现:
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: